商圏分析 用語集
クラスター分析(クラスタリング)
クラスター分析とは、大量のデータがあるとき、異なる性質のものが混ざりあっている集団(対象)の中から互いに似たものを集めて集落(クラスター)を作り、それぞれの距離を計算することで対象を分類する手法です。商圏分析では、店舗の属性や商圏特性に応じた品揃えを行うために店舗を分類し、商品構成の欠落(売れるはずなのに品揃えしていない)を防止したりしています。マーケットアナライザー(MarketAnalyzer™)シリーズでは、店舗クラスター分析機能を搭載することができます。
クラスター分析の基礎情報
クラスター分析には複数の種類があります。大別すると「階層的クラスター分析」と「非階層的クラスター分析」があり、それぞれに細かい計算アルゴリズムがあります。
■階層クラスター
階層クラスター分析の計算アルゴリズムには以下のものがあります。
・ウォード法 ・最短距離法(最近隣法)
・最長距離法(最遠隣法)・メディアン法
・群平均法・重心法・可変法
最も使用頻度が高いのはウォード法です。利用者からも、各クラスターのサンプル数が最もうまく分類される使い勝手の良い手法として評価されています。
階層クラスター分析を行うと、単に対象をいくつかのクラスターに分類するだけでなく、どのようにクラスターが結合されていくかの過程までが見られる直観的なアウトプット、樹形図(デンドログラム)が得られます(図2)。欠点は、クラスター分析の対象が多い場合、計算量が非常に多くなり実行不可能となったり、結果が不安定となることがあります。このような特長があるため、次に紹介する非階層クラスター分析が用いられることがあります。
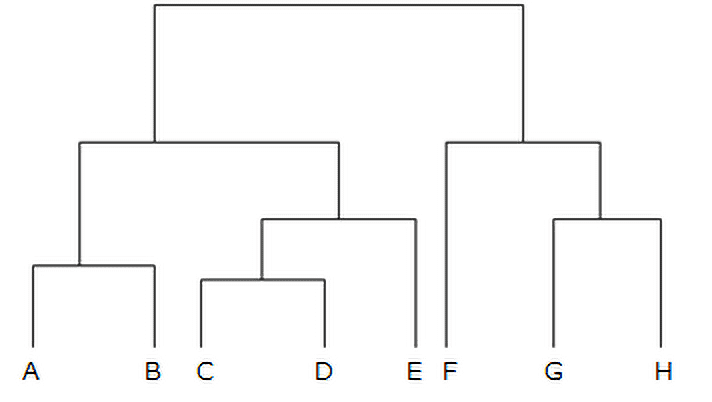
【図2 樹形図(デンドログラム)】
■非階層クラスター
非階層クラスター分析の計算アルゴリズムには以下のものがあります。
・k-means法 ・超体積法
階層クラスター分析にせよ非階層クラスター分析にせよ、分類する対象がそれぞれ、どれほど「近い」か、もしくは「似ているか」を数量的に表すことを通じて分類されます。
その際に使われるのがユークリッド距離やマハラノビス距離です。ユークリッド距離は下式で表されます。
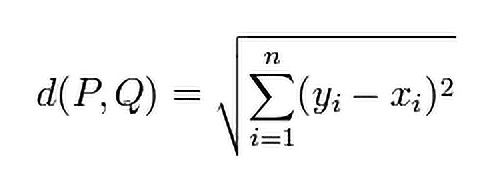
この式はサンプルP、Q間の距離を意味します。この距離の値により、「近い」「似ている」を判定しています(図3)。
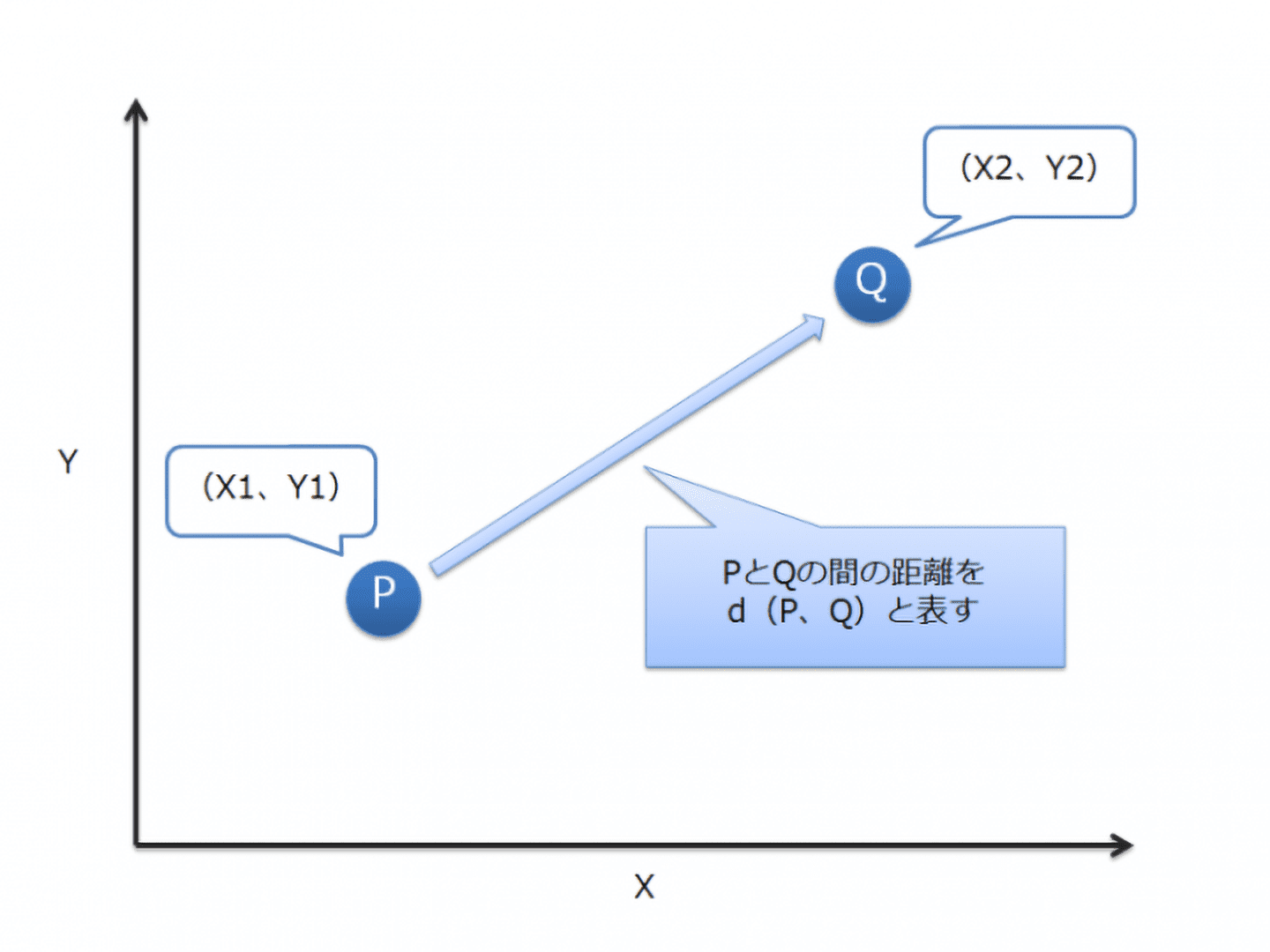
【図3 ユークリッド距離の概念】
非階層クラスター分析(k-means法)のアルゴリズム
代表的なクラスター分析として、非階層クラスター分析(k-means法)のアルゴリズムのポイントをご紹介します。非階層クラスター分析(k-means法)は、次のような流れで計算が行われます。
まず、分析対象となるサンプルがあります。図4は個々のサンプルが持つ特性(例:需要と供給)の違いにより、サンプルのポジションをイメージ化したものです。
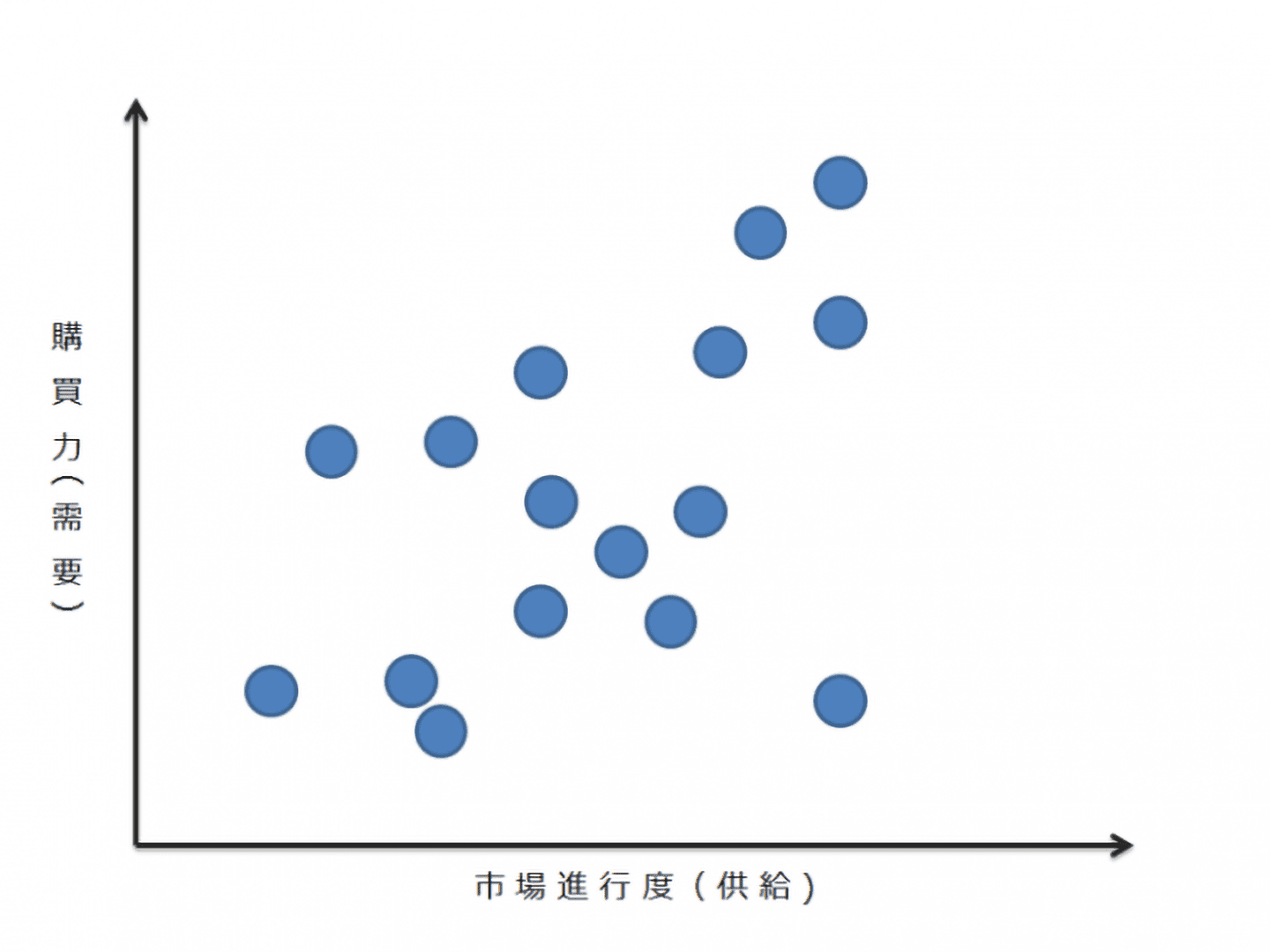
【図4 サンプルの分布】
非階層クラスター分析では予め、サンプルを分類する数を指定します。その分類の数だけ、各分類の代表点となるシード(seed、種)が作られます。図5はサンプルを4つに分類した例です。初めのシードはサンプルからランダムに選ばれます(●●●●)。
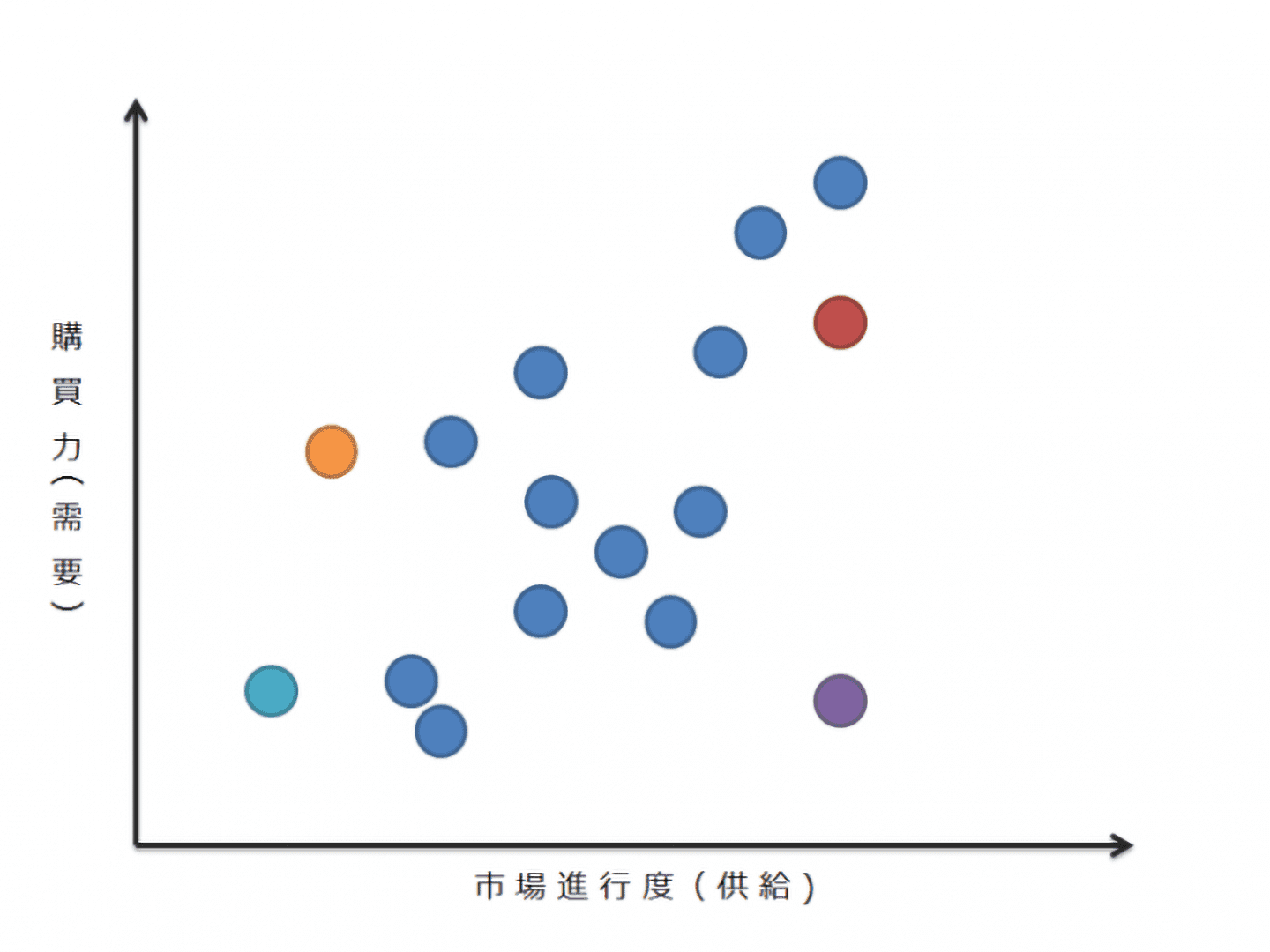
【図5 シードの設定】
シードと他のサンプル間の距離を求め、それぞれのシードと近い関係をもつサンプルが分類されます(図5)。
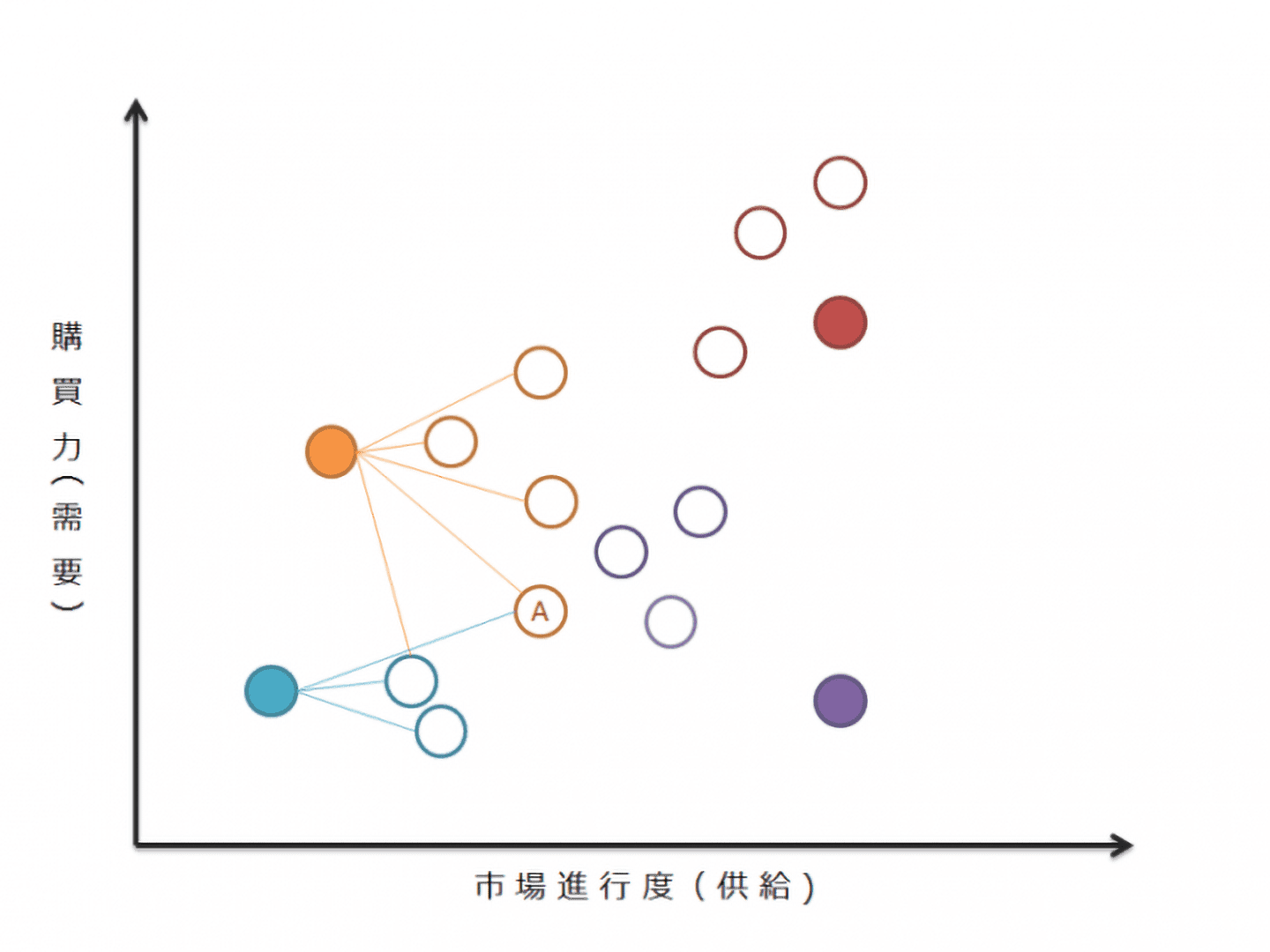
【図5 サンプルの分類(1回目)】
初期の設定シードを変更(★★★★)していき、各シードと分類後の各サンプルとの距離が安定するまで繰り返されます。図5の●Aは初回の分類では●でしたが、最終的には●に分類されました(図6)。
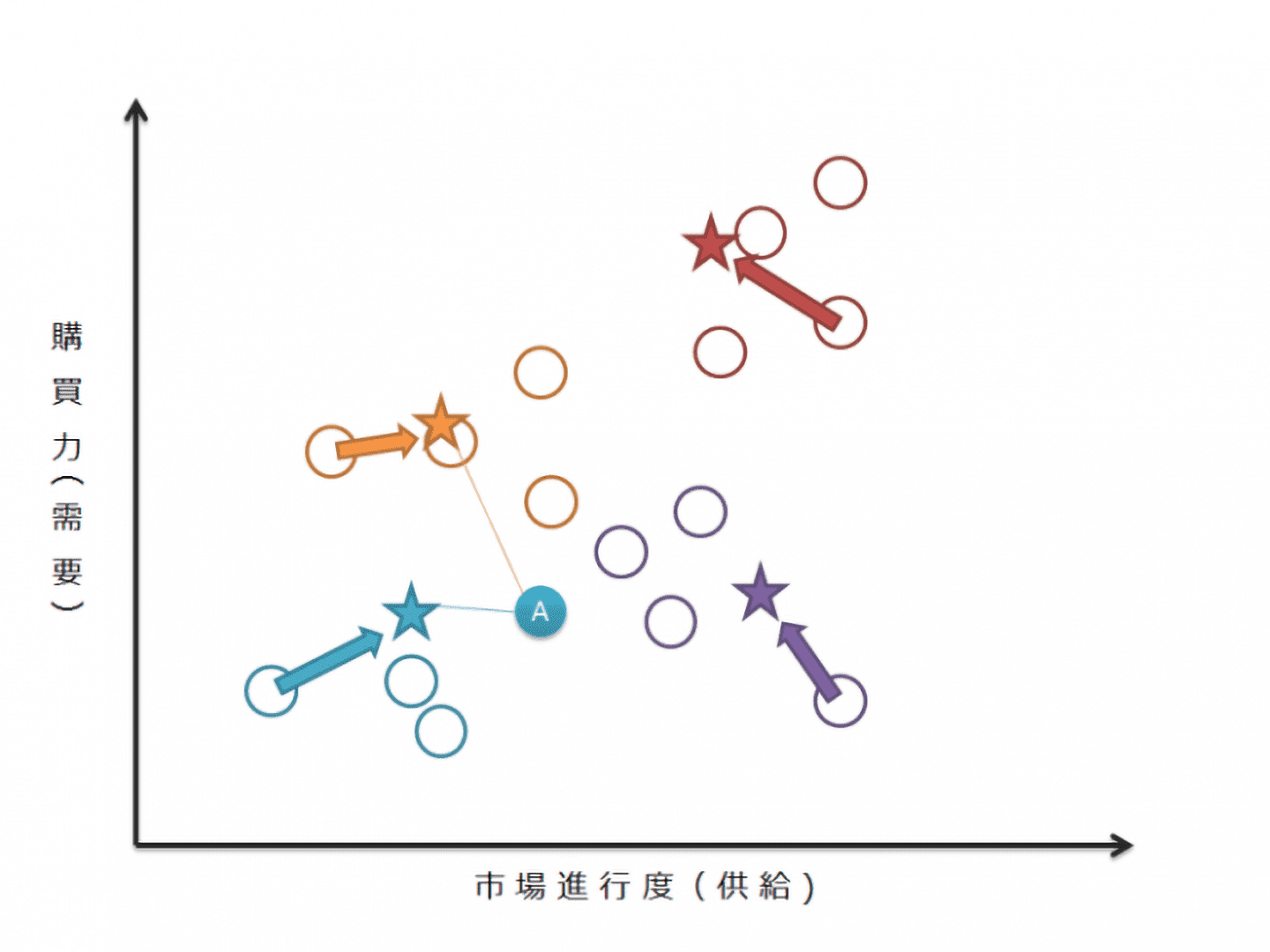
【図6 サンプルの分類(2回目~)】
このように、クラスター分析は反復計算を経て結果が導き出されるため、計算量が膨大となり、処理時間が長くなることに注意が必要です。
SCのクラスター分析
全てのSCを一律に評価・分析することはできません。売上規模・営業面積・キーテナント・SCのブランド・立地というような軸に基づいて分けるべきでしょう。今回は立地をテーマとし、SCの商圏特性の評価軸として「ベッドタウン性・繁華街性・ビジネス街性」という3つの要素を用いてSCを分類します。分類手法は「クラスター分析」を採用します。クラスター分析とは統計解析のひとつの手法で、異なる性質のものが混ざりあっている集団の中から互いに似たものを集めてグループ(クラスター)を作り、対象を分類するという方法を総称したものです。分類ロジックには階層クラスター分析と非階層クラスター分析など様々なものがあります。MarketAnalyzer™には商圏データ一括集計機能やクラスター分析機能があるため、簡単に作業を行うことができます。
先の3つの要素に対応するデータとして、ここでは国勢調査の夜間人口、リンク統計の昼間人口、推計商業統計データの小売業年間販売額を用います。商業統計の小売業年間販売額は、最新の2012年調査を基に、当社独自のロジックで作成した項目です。
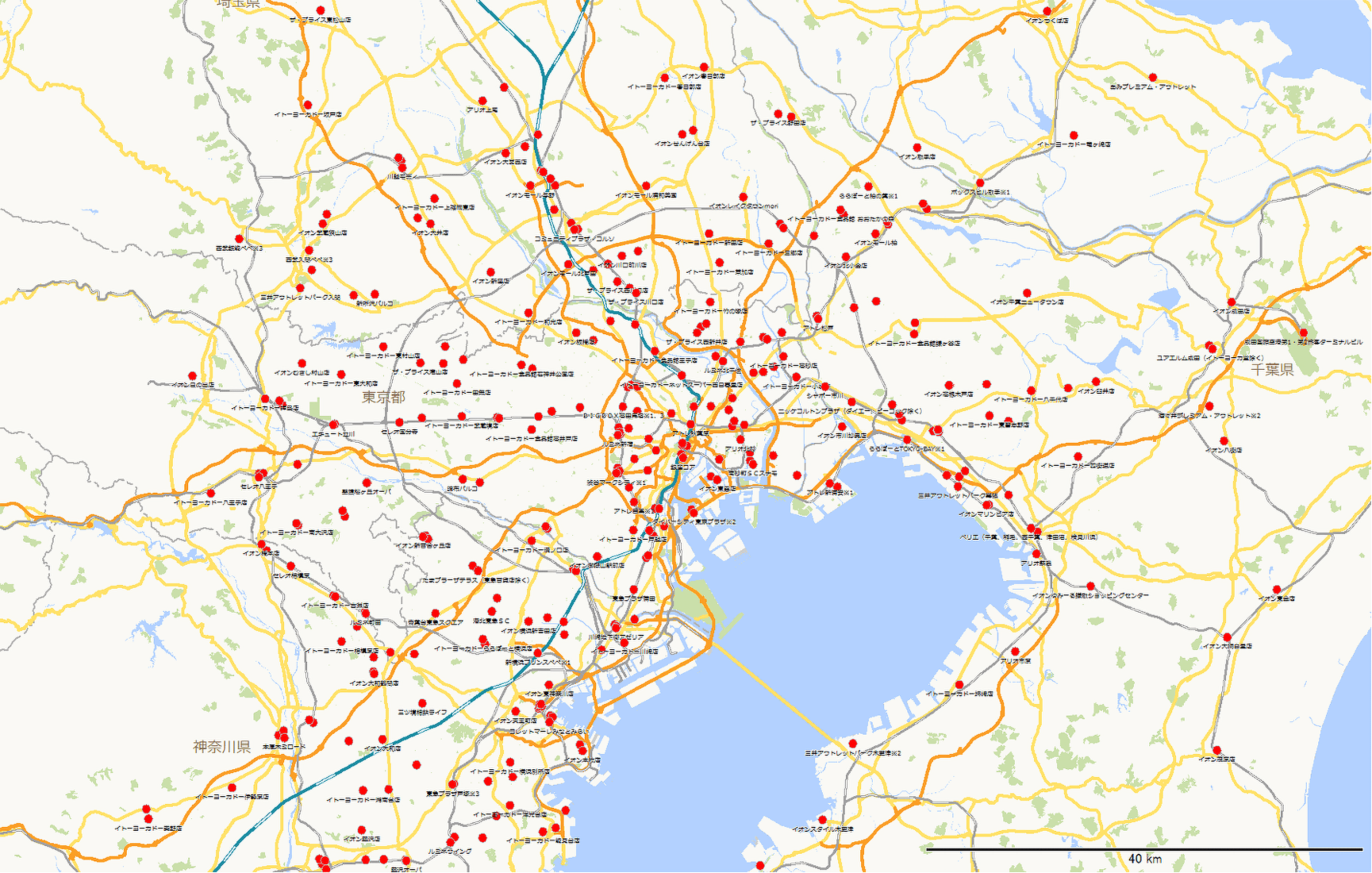
【図1:主要商業施設データのSC分布】
まず、図1の主要商業施設データの中の約1,000店舗に対して、一律半径3km商圏を設定し、3つの指標を集計します。そして、集計した3つのデータを用いて1,000店舗を5つにクラスタリング(分類)しました。
図2の地図に表示されている丸い点がSCの分布です。クラスター毎に色が分かれています。地図を俯瞰してみると、クラスターCL004(黄色い点)は山手線の内側に集中しており、それを取り囲むようにCL002(ピンク)、CL005(紫)、CL003(黄緑)が分布しています。CL001(水色)は一部のエリアに見られます。
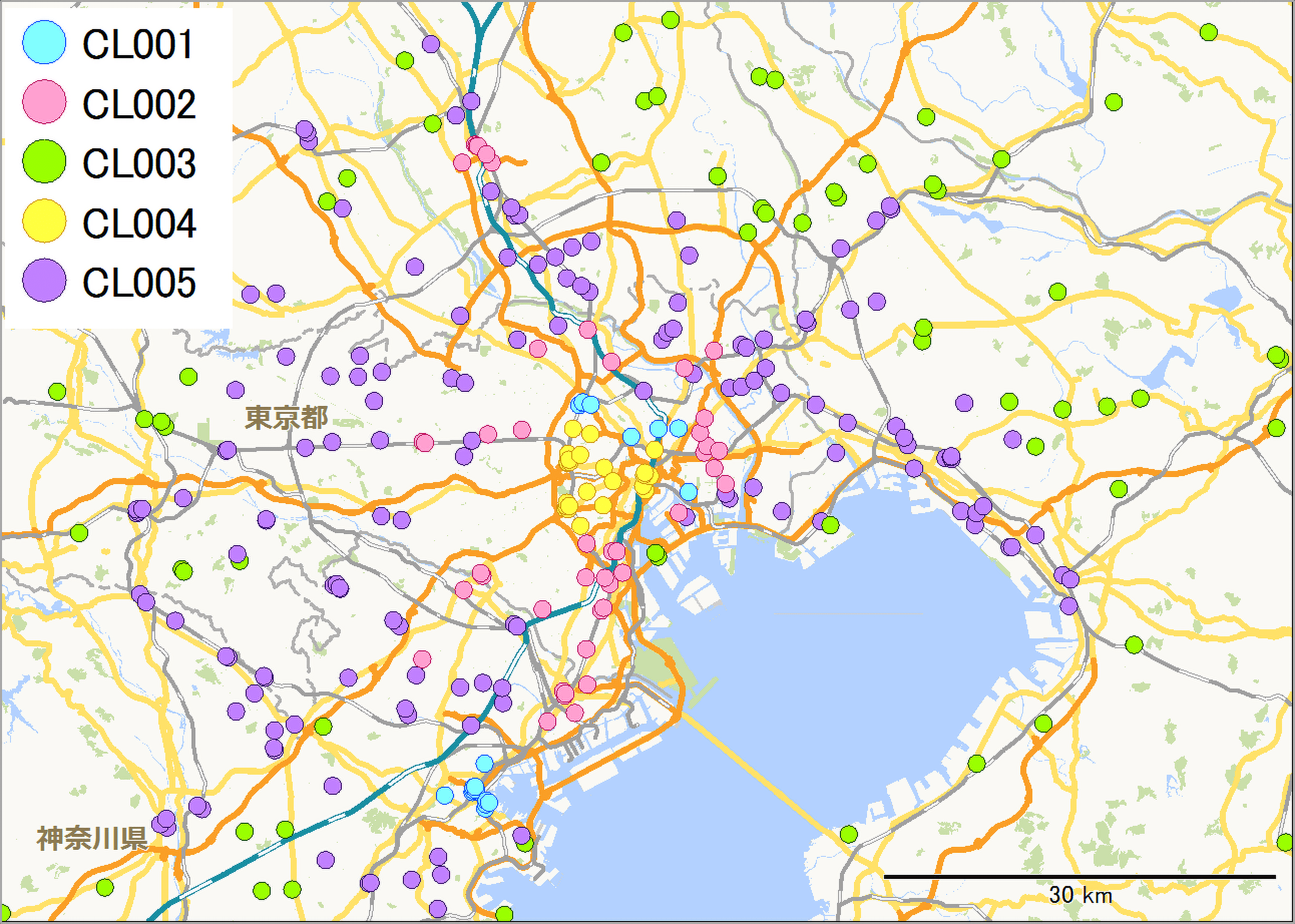
【図2:クラスターごとのSC分布】
次に、各クラスターを解釈するため、クラスターごとに3つのデータを集計します(図3)。
縦軸がクラスター、横軸は3つのデータです。夜間人口をベッドタウン性、昼間人口をビジネス街性、小売業年間販売額を繁華街性と記載しています。数字はZスコア(ゼロを真ん中とする偏差値)となっています。
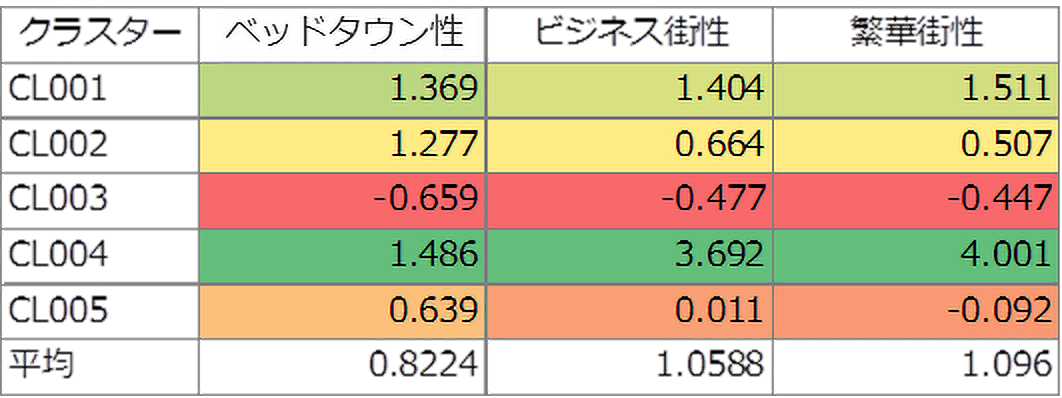
【図3:クラスターごとに3つの指標を集計】
CL004のクラスターは全ての指標において突出しており、CL001が次に続いています。CL003は全ての指標が最も低く、CL002とCL005はベッドタウン性に寄っている傾向と解釈しました。
このように客観的なデータで分類し、成功事例の横展開をグループ内店舗で行ったり、同じグループ内で各種評価・比較をします。図4はCL004(全ての指標が突出しているグループ)に属するSCを半径3km圏内の昼間人口ボリュームが多い順に並べたものです。一方で図5は夜間人口でのランキングです。東京の丸の内は昼間人口≒ビジネス街性が高い、高田馬場・早稲田≒ベッドタウン性が高いということでしょう。
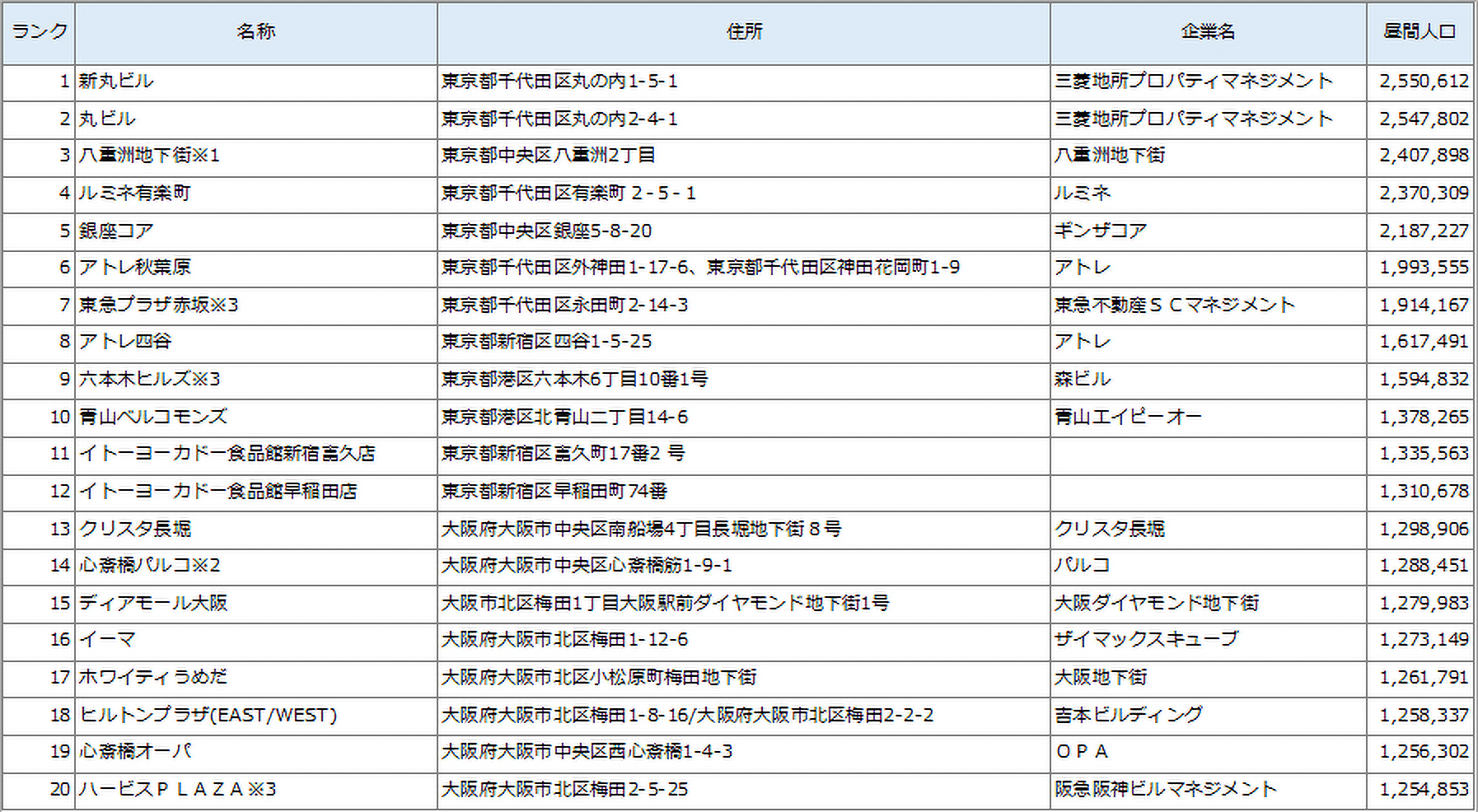
【図4:CL004の昼間人口ボリュームSCランキング】
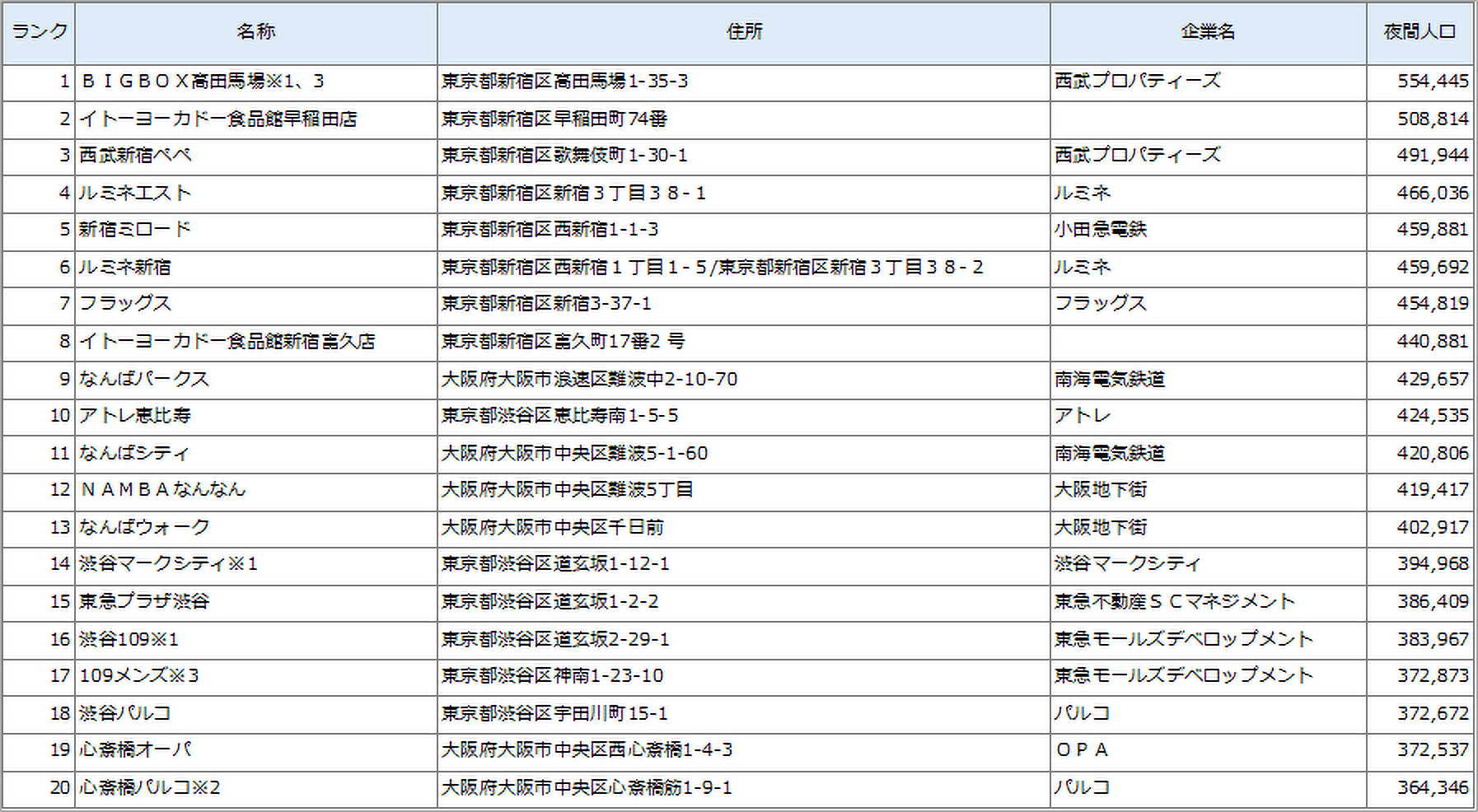
【図5: CL004の夜間人口ボリュームSCランキング】
類似商圏検索
次に、似ている商圏を持つ店舗はどれかという類似商圏の検索手法をご紹介します。商圏特性とターゲットボリュームが似通っていれば目標とする売上を同じレベルに設定したり、ある店舗での施策が成功したら、その類似店舗で成功事例を横展開したりします。また、新規出店対象のSCの売上を想定するために、出店候補施設と類似した商圏を持つ施設に出店している既存店舗の売上を参考にすることもできます。
今回は課題の設定例として、既にテナントをアトレ恵比寿に出店しており、その売上が好調なのでアトレ恵比寿と商圏が類似しているSCを探すということにします。
まずターゲット層を20代~30代の女性と定義しました。全国のSC半径3km圏で国勢調査から20~30代女性夜間人口を集計し、更に推計年齢別昼間人口データから20~30代女性昼間人口を集計して商圏データを作成しました(図6)。
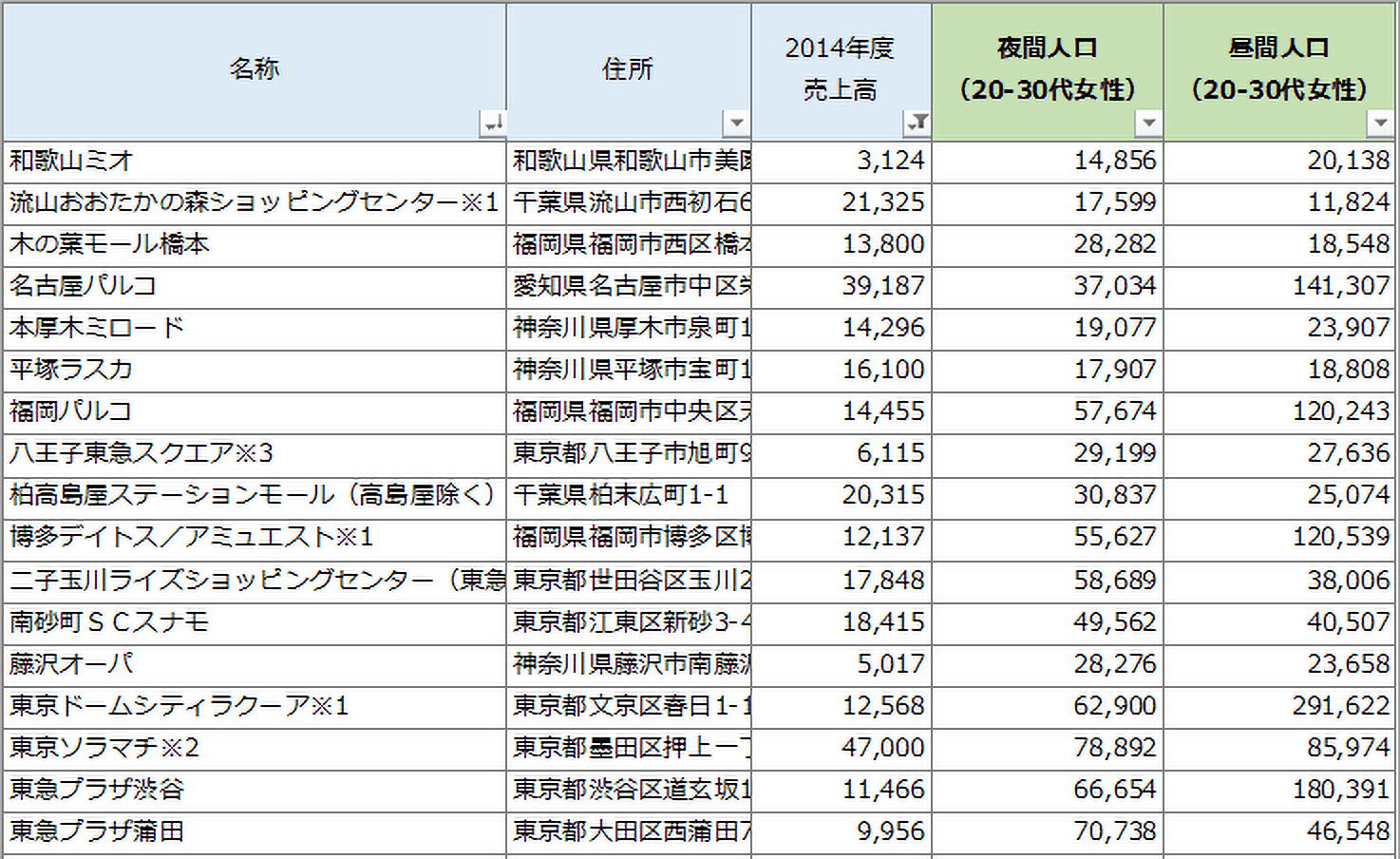
【図6:SC半径3km圏内のターゲット商圏データ】

【図7:アトレ恵比寿と商圏が類似しているSC】
この2つの指標に更にSCの売上という要素を加えました。それぞれの指標を串刺しで分析するために実数ではなく、スコア(偏差値)に変換し、それぞれの偏差値が±5に収まるSCを抽出しました(図7)。結果として新宿ミロード、なんばウォーク、なんばパークスが該当しました。
最後に、今回の分析は、商圏分析用GIS(地図情報システム)「マーケットアナライザー(MarketAnalyzer™)」を用いて行いました。ご興味をお持ちいただきましたらお気軽にお問い合わせください。
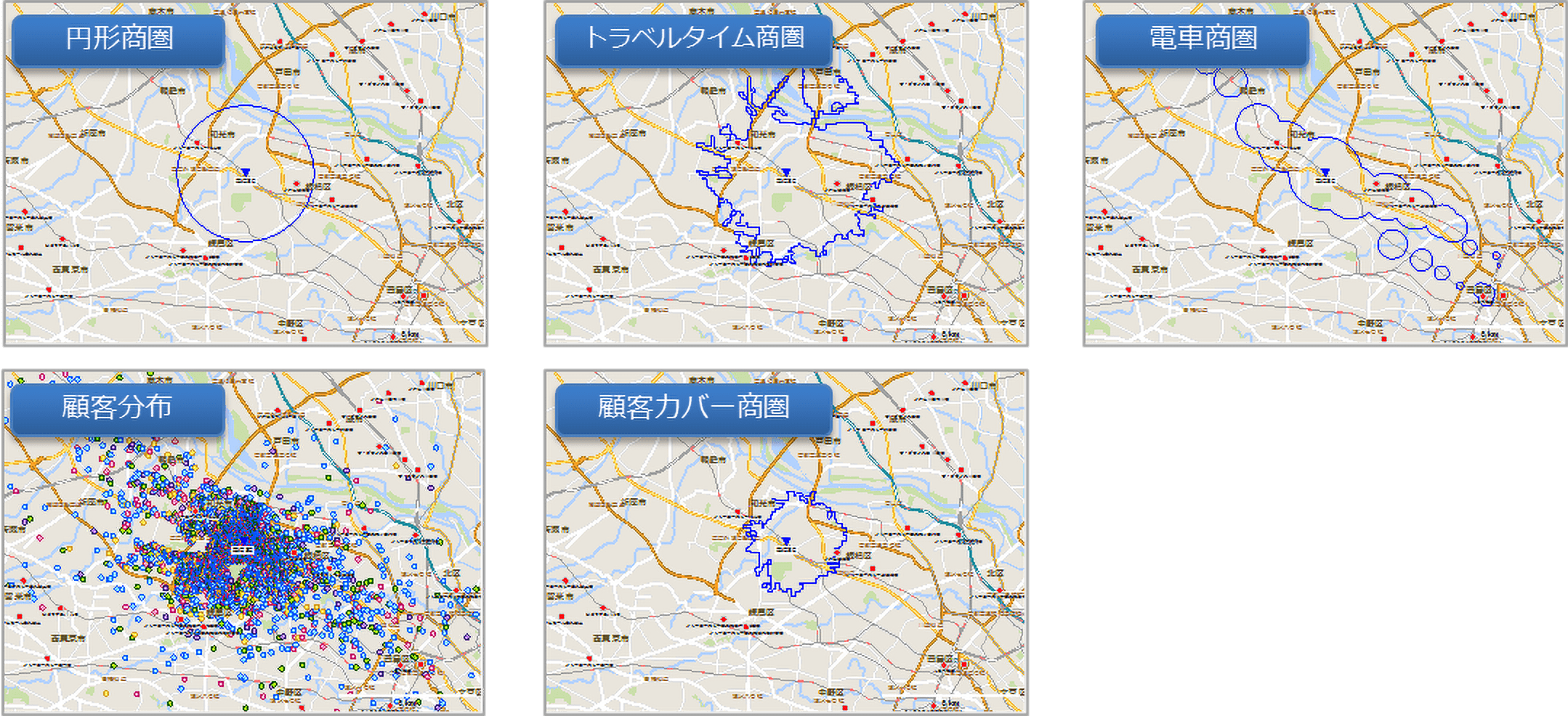
様々な商圏タイプ(一部)