
エリアマーケティングラボ
【セミナーレポート】商圏分析GISがもたらすエリアマーケティングDX(後半)
2025年4月15日号(Vol.142)
はじめに
本コラムは2025年4月4日開催したオンラインセミナーのレポートです。
「出店候補地の商圏をデータで読み解く」という後半のパートの一部をご紹介します。
後半は、エリアのポテンシャルを明確に把握するために必要な分析ノウハウを、9つのキーワード毎に解説します。
「エリアマーケティングのDXを進めたい」、「データを駆使した出店候補地の選び方を学びたい」、「エリアや顧客を理解するために、統計データや自社データを活用していきたい」、という課題をお持ちの方、必見です。
〇 前半はこちら

商圏データのしきい値、判断基準
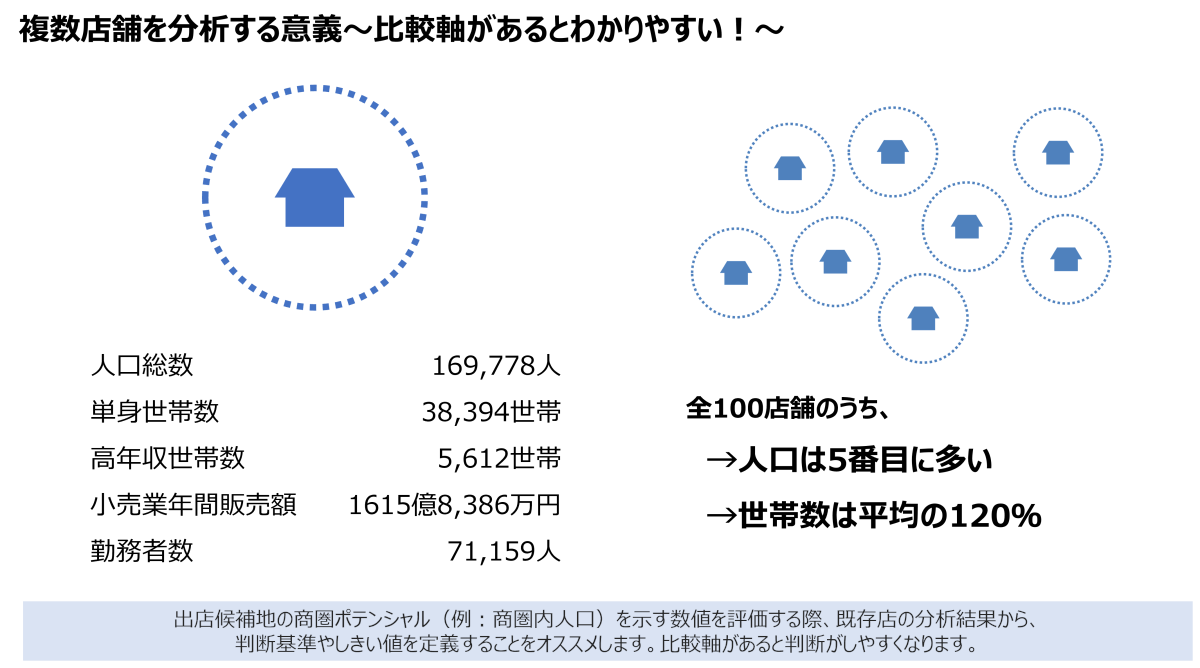
GISを活用した商圏分析においては、例えば「車で10分圏内に人口が16万9,000人いる」といったデータだけでは、その数値が多いのか少ないのか判断が難しいという課題があります。
そこで重要になるのが、判断基準や“しきい値”の設定です。例えば、チェーン企業が全国に100店舗あり、その中でこの人口規模が5番目に多い、あるいは平均15万人に対して2割多いといった比較ができれば、そのエリアのポテンシャルがより明確になります。
このように、まずは既存店データとの比較を通じてしきい値を設定し、各指標の見方を明確にすることが、GIS導入初期に重要なステップです。
既存店舗データのマッピング、商圏データの一括集計
商圏分析を行うにあたっては、まず企業が保有する既存店舗のリストをGISに取り込む作業から始まります。これは1行に1店舗の情報を記載したリストで、例えば店舗名、住所、売上などが含まれます。今回のデモではサンプルのダミーデータ(約100店舗)を使用していますが、実際には1万店舗以上のデータにも対応可能です。このリストをインポートし、GIS上にマッピングすることで、店舗の所在地が地図上にプロットされ、視覚的に確認できるようになります。住所情報は漢字表記で読み取り、正確性によって位置の精度が変わるため、読み取り精度のチェックも重要です。
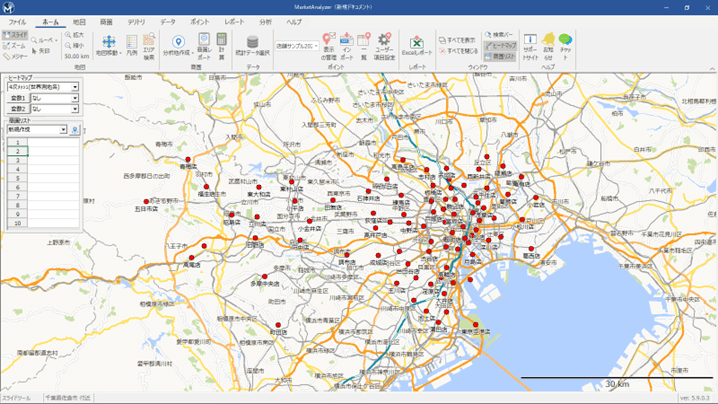
さらに、インポートした店舗データに対して、各店舗の半径1km圏内の商圏データを追加する作業が行われます。たとえば商業人口や年収別世帯数、昼間・夜間人口など、今回は15項目を選んで集計を実行しました。システムは各店舗の周囲に円を描き、指定された項目を迅速に集計します。処理が完了すると、元の店舗リストに新たな15列が追加され、各店舗ごとの商圏データが反映されます。これにより、商圏特性を効率的に可視化・分析できるようになります。
散布図で既存店全体を俯瞰する方法
既存店のリストを俯瞰して分析するには、表形式では分かりづらいため、グラフ化するのが基本です。具体的には縦軸に売上、横軸に1km圏内の夜間人口をとった散布図を作成することで、各店舗のポジションが視覚的に把握できます。右下に位置する店舗は商圏ポテンシャルが高いのに売上が低く、改善の余地があると判断できます。
一方、左上に位置する店舗はポテンシャルが低くても売上が高いため、成功要因を分析して他店舗に展開するヒントになります。こうした俯瞰的な視点が分析の本質です。
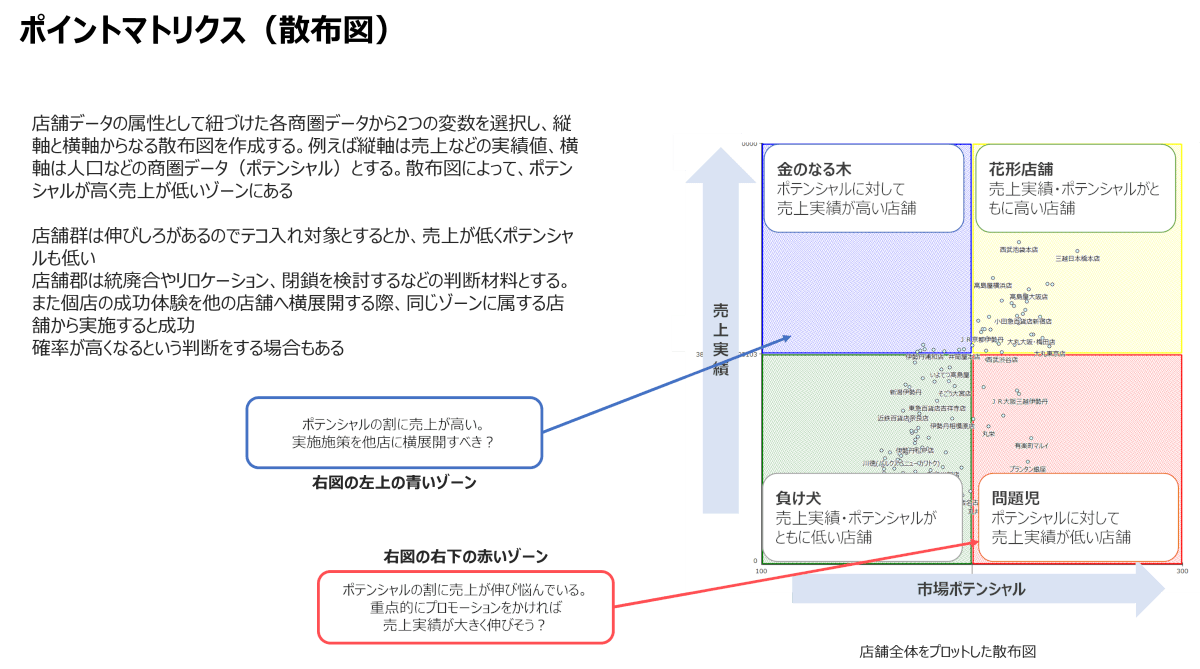

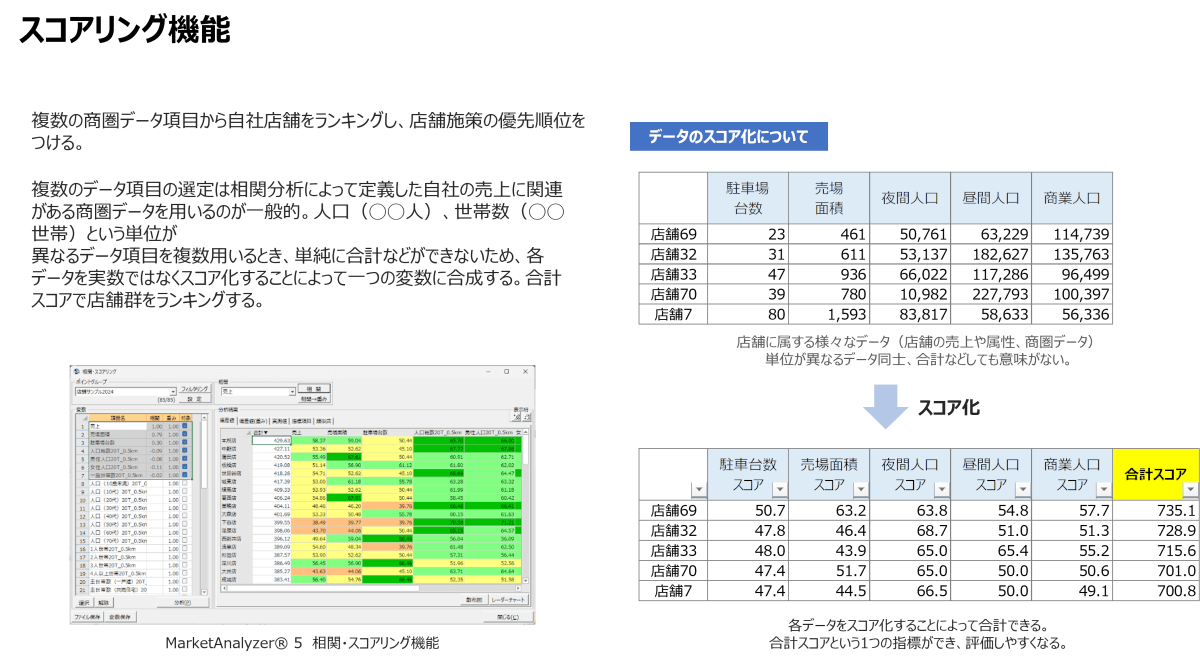
店舗商圏の相関・スコアリング分析
商圏分析の精度を高めるには、単一の指標だけでなく複数の商圏データを組み合わせた相関・スコアリング分析が有効です。従来は売上を縦軸、夜間人口を横軸にとるシンプルな散布図が使われがちですが、夜間人口だけではポテンシャルを正確に捉えきれないことがあります。
そこで、複数の商圏指標(例:商業人口、年収別世帯数など)を活用し、それぞれのデータを偏差値に変換してスコア化します。これにより、異なる単位のデータも一括評価が可能になります。さらに、売上との相関係数を確認しながら、相関が高いデータのみを選択することで、スコアの信頼性を高めることができます。最終的に、各店舗に対してスコアを付けることで、売上に寄与している商圏要素を可視化でき、戦略的な店舗運営や出店判断に活用できます。これにより、単純な散布図よりも実態に即した、より精度の高い分析が可能になります。
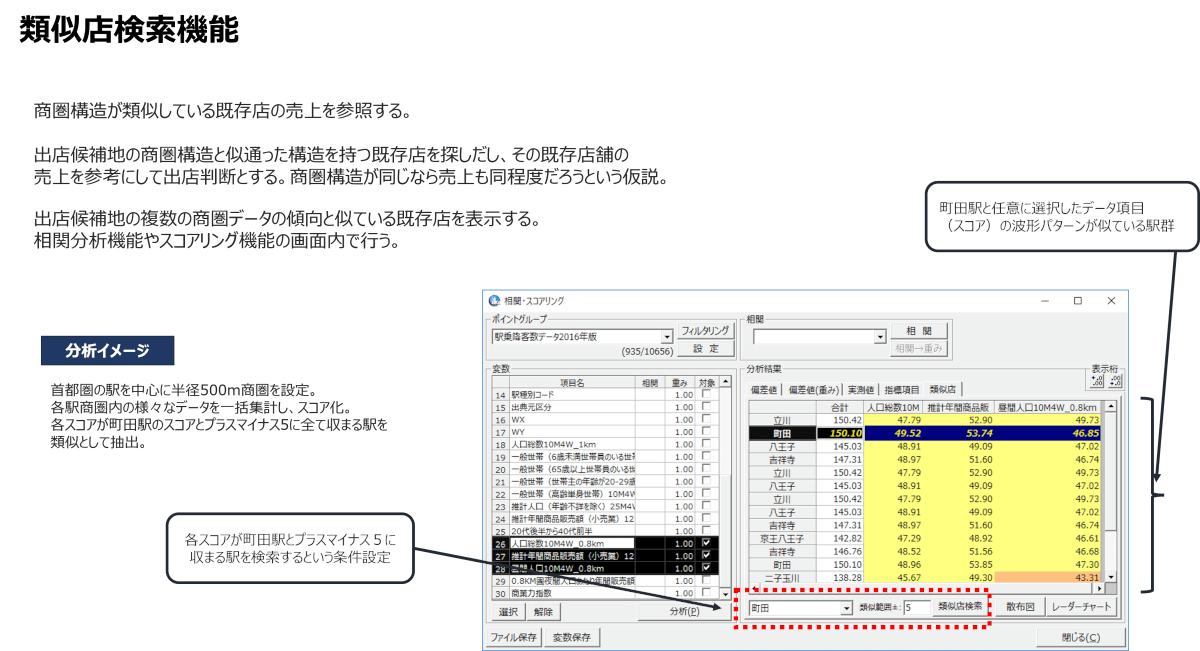
類似店検索機能
類似店舗(商圏)検索は、新店候補地の商圏特性に近い既存店を自動で抽出し、出店判断の参考にする分析手法です。
例えば、浅草店が新店候補地であれば、商圏構造が似ている杉並店や練馬店を比較対象として抽出し、それらの売上を基に将来の売上見込みを推定することができます。これはあくまで参考値ですが、出店可否の判断材料として有効です。この分析は、商圏データを偏差値スコア化し、売上と相関の高い指標のみを選定することで、精度を高めています。標準機能として提供されており、特に地域密着型の企業から高評価を得ています。また、応用編としては駅周辺やショッピングモールのような拠点単位での類似性分析も可能です。たとえば、町田駅と立川駅のように、似た特性のエリアでの出店戦略を考えることができ、モール内テナント選定の事前検討にも活用できます。企業の出店判断や営業戦略に幅広く貢献する分析機能です。
クラスター分析
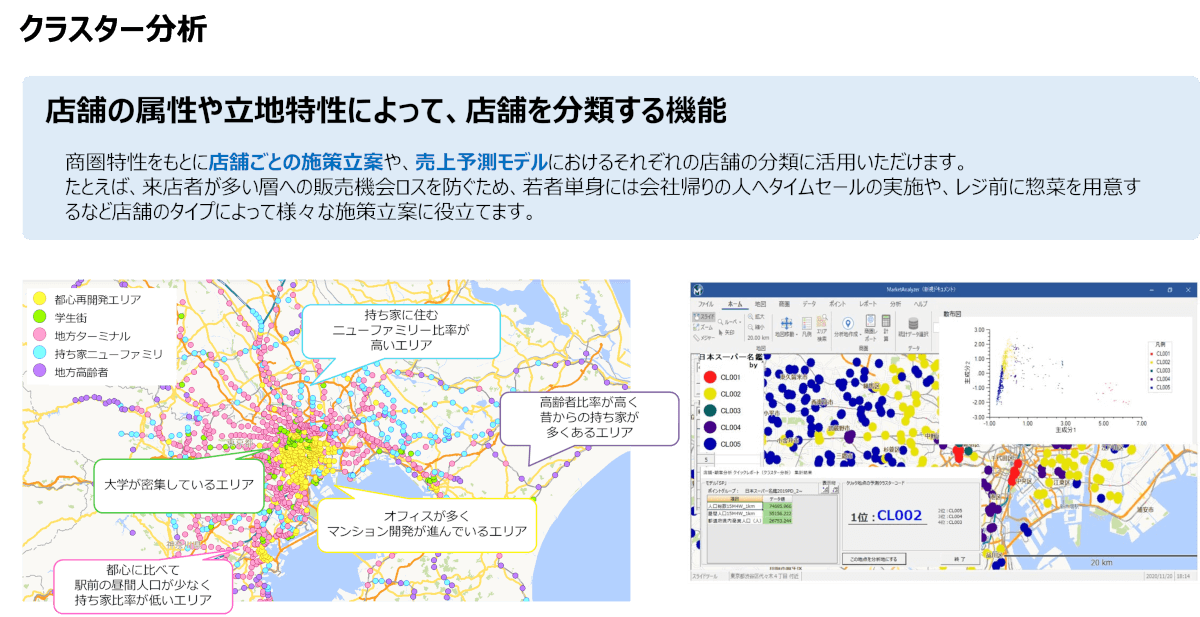
クラスター分析は、複数の店舗を商圏構造の類似性によってグループ分けし、それぞれの特徴を把握することでマーケティングや戦略立案に活用する手法です。
今回は応用的な統計解析として、クラスター分析と重回帰分析を紹介しています。
具体的には、事前にさまざまな商圏データ(商業人口・昼間人口・夜間人口など)を付加した85店舗を対象に、3つの人口データを使って5つのグループに分類。クラスター分析機能を使ってモデルを作成し、店舗を色分けして地図上に表示することで、視覚的にもわかりやすいグループ分けが可能になります。
例えば、新宿・渋谷・銀座などの繁華街型、麻布・赤坂などのオフィス街型、郊外のベッドタウン型など、地域ごとの特性が分類結果として現れます。さらに、「インデックス」機能を使うことで、各クラスターにおける各項目のスコアを可視化し、数値的な違いも確認可能。これにより、たとえば商圏構造が似たグループ内での売上モデルの作成や、成功事例の横展開、品揃えや販促戦略の最適化など、より精度の高い分析が可能になります。標準機能でありながら、応用的な活用も期待できる強力な分析手法として、多くの企業に評価されています。
重回帰分析
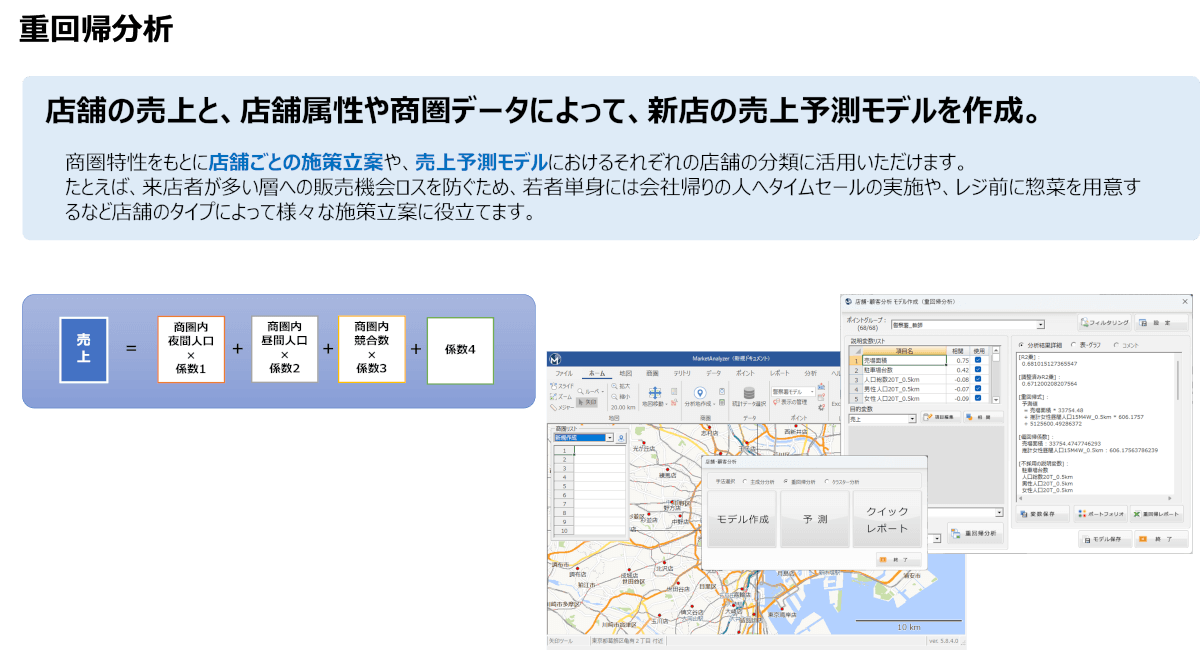
重回帰分析は、売上予測を目的とした統計解析の一手法で、複数の説明変数(要因)から売上を予測する数式を導き出します。この分析も標準機能に含まれており、専門的な知識がなくても簡単な操作でモデルを作成できます。まず、予測したい対象(例:売上)を選択し、それに影響を与えると考えられる商圏データ(中間人口や店舗周辺の世帯数など)を選びます。必要なデータが事前に取り込まれていれば、ボタンをクリックするだけで予測モデルが自動生成されます。
生成されたモデルは「売上=各変数×係数+…」の形式で示され、どの変数がどの程度売上に影響を与えているかが明確にわかります。モデルの精度は、実測値と予測値の相関係数(R²)で確認できます。たとえばR²=0.64であれば、予測精度は高いと判断されます。この結果をもとに、さらに変数を入れ替えたり、詳細なデータに変更したりすることで、精度の向上も可能です。
モデルが完成したら保存しておき、新たに出店候補地が出てきた際にその地点をクリックし、面積などの基本条件を入力することで、即座に売上予測が表示されます。これにより、現場の担当者でも直感的かつ迅速に出店判断を行えるようになります。なお、現在AIや機械学習を活用した高度な予測モデルの開発も進行中であり、さらなる精度向上にも期待が寄せられています。売上予測は多くの企業が最終的に行き着く重要なテーマであり、今後の進化も注目されています。
〇 [関連コラム]重回帰分析とは?分析手法や活用事例を紹介
商圏人口と吸引人口
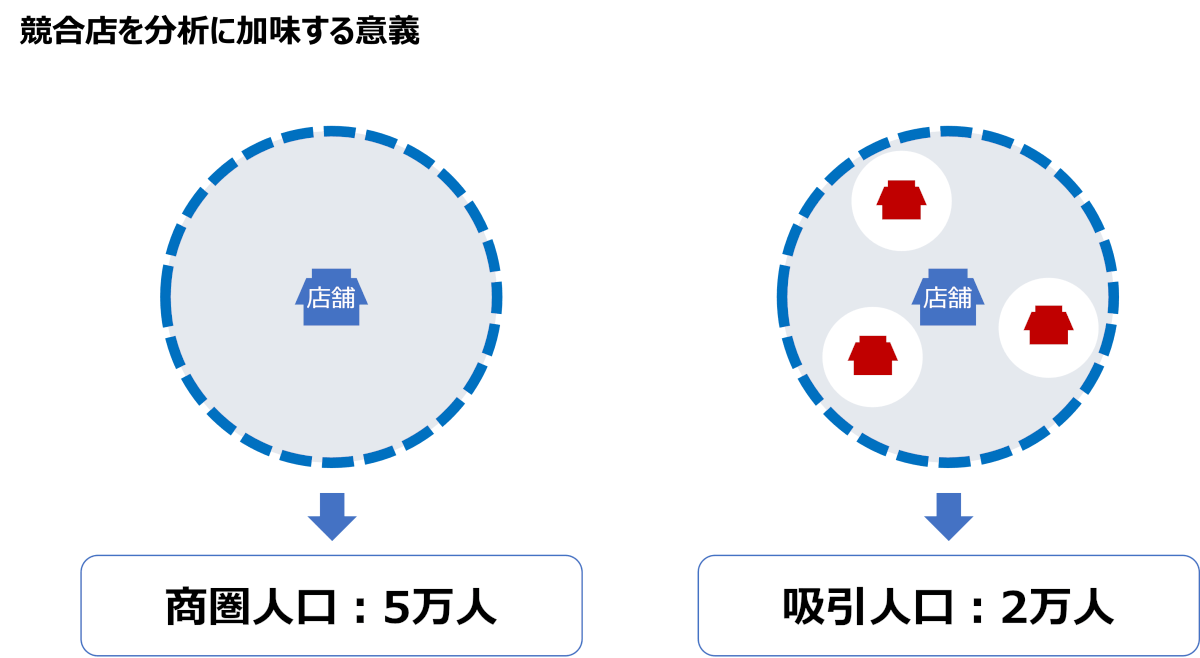
商圏分析において重要なのは、単に商圏人口(例:5万人)を見るだけでなく、競合店舗の存在を踏まえた「吸引人口」も考慮することです。たとえ商圏内に5万人の住民がいても、競合店の影響により実際に自店に来る可能性があるのは一部で、例えば2万人に減ることもあります。この「吸引人口」こそが現実的な市場規模であり、両方の指標を併せて見ることが重要です。
ハフモデル
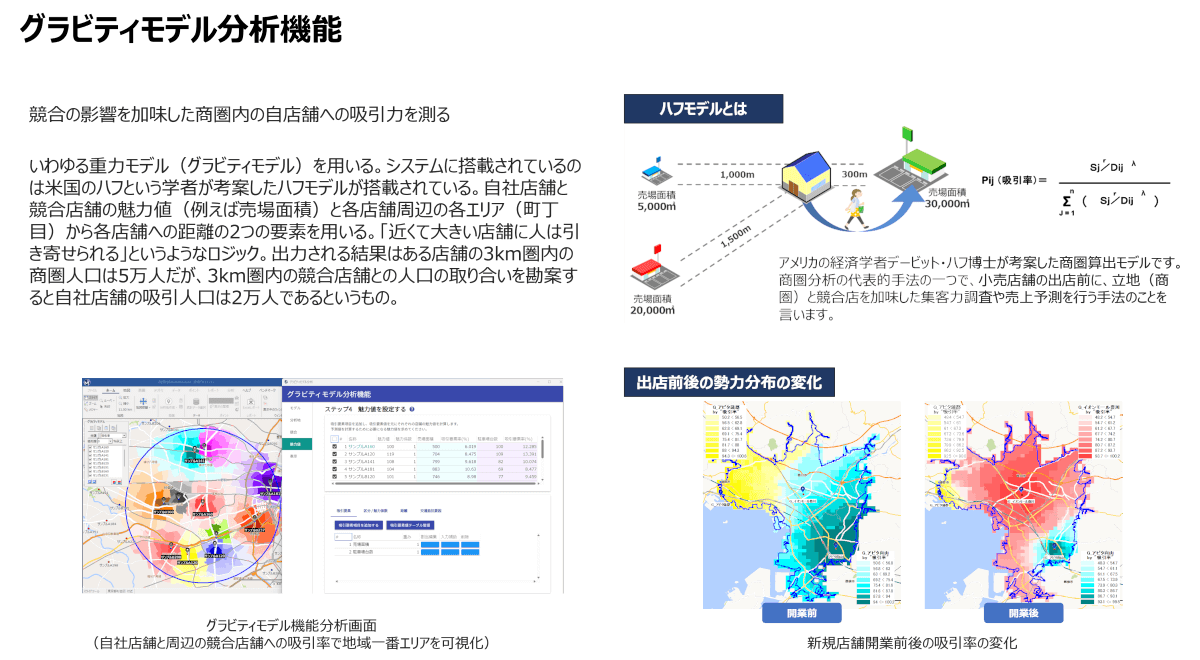
ハフモデルとは、アメリカのデイビッド・ハフ氏が提唱した、距離と店舗の魅力度に基づいて消費者の来店確率を算出する「重力モデル」の一種です。ある地点に住む人が複数の店舗の中からどこを選ぶかを確率的に予測することができます。たとえば、あるエリアに住む100人のうち、特定の店舗への吸引率が10%であれば、その店舗に来店するのは10人と見積もることができます。これにより、各エリアからの来店者数を積み上げることで、店舗全体の吸引人口を推定できます。
■ハフモデル分析(グラビティモデル分析)デモンストレーション
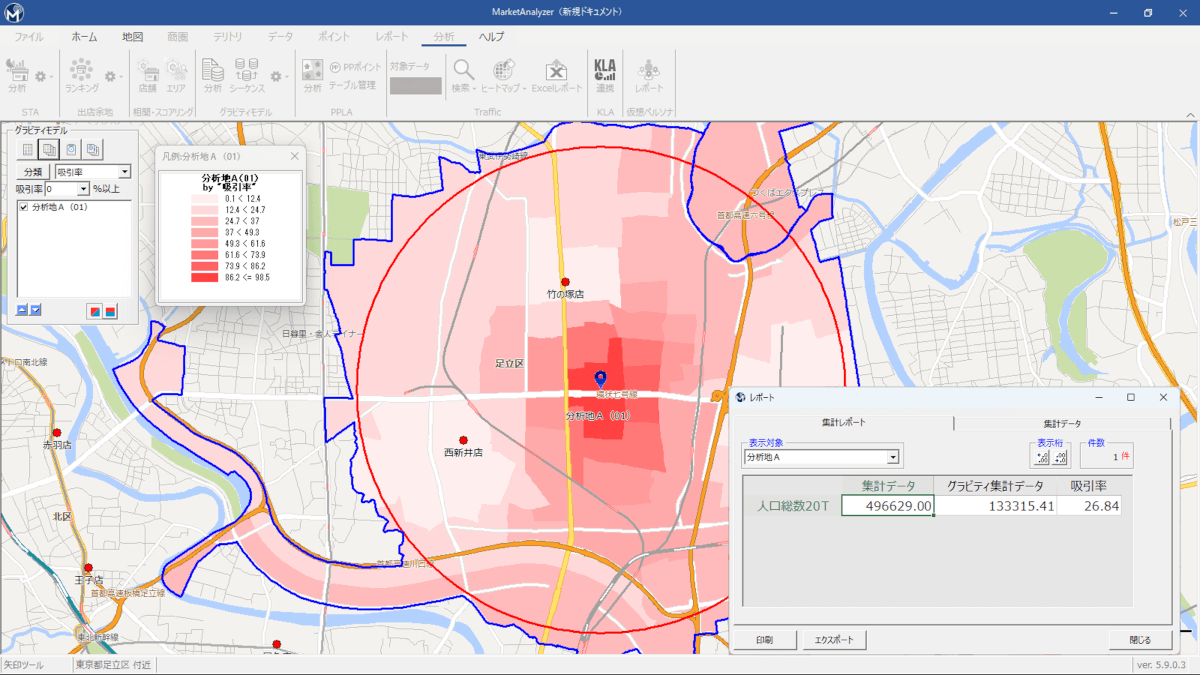 ハフモデル(グラビティモデル)分析のデモンストレーションでは、実際の店舗と競合店舗を地図上に設定し、商圏内の消費者がどの店舗にどれだけ吸引されるかを分析します。分析対象の自社店舗を設定し、半径4キロ圏内の商圏を定義。さらに周辺の競合店舗を選択・確認し、ハフモデルを適用します。
ハフモデル(グラビティモデル)分析のデモンストレーションでは、実際の店舗と競合店舗を地図上に設定し、商圏内の消費者がどの店舗にどれだけ吸引されるかを分析します。分析対象の自社店舗を設定し、半径4キロ圏内の商圏を定義。さらに周辺の競合店舗を選択・確認し、ハフモデルを適用します。このモデルは、「距離」と「魅力値(今回は売場面積)」の2要素をもとに、店舗ごとの吸引率を算出します。近くて大きい店ほど吸引力が高いという考え方です。魅力値は売場面積以外にもブランドイメージなどを加味することで、より現実的な分析が可能になります。
その後、各地域からの店舗への吸引率に、該当地域の人口を掛けることで「吸引人口」を算出。たとえば、対象商圏には約91万人が住んでおり、分析の結果、自社店舗の吸引人口は18万7千人と推定されました。これにより、単純な商圏人口ではなく、競合の影響を加味した実際の市場規模を把握することができます。
地図上では、吸引率の高い地域が濃い色で示され、自店舗の商圏中心部は色が濃く、競合店の足元では薄くなるなど、直感的に競争状況を視覚化できます。こうした分析により、商圏評価の精度を高めると同時に、立地戦略や販促戦略の立案にも活用可能です。
〇 MarketAnalyzer® 5グラビティモデルの詳細はこちら
まとめ
GISを活用した商圏分析では、商圏データの「しきい値」や判断基準の設定が重要です。
例えば、店舗周辺の人口データを既存店舗と比較することで、エリアのポテンシャルを明確化できます。また、既存店舗データをGISに取り込み、地図上にプロットすることで視覚的な分析が可能となります。この際、住所情報の正確性が分析精度に影響するため、注意が必要です。さらに、半径1km圏内の商圏データを集計し、各店舗ごとの特性を効率的に可視化します。
分析手法としては、売上や夜間人口などを軸に散布図を作成し、店舗ポジションを俯瞰的に把握する方法があります。これにより、改善が必要な店舗や成功事例の特定が可能です。また、複数の商圏指標を偏差値化してスコアリング分析を行うことで、売上への寄与度が高い要素を特定し、より精度の高い分析が実現します。
新店候補地の商圏特性に近い既存店舗を抽出する「類似店舗検索」も有効です。これにより売上予測や出店判断の参考材料が得られます。また、クラスター分析では商圏構造の類似性によって店舗をグループ化し、それぞれの特徴を把握することで戦略立案に役立てます。
さらに、重回帰分析は複数の要因から売上予測モデルを構築する手法であり、簡単な操作で精度の高い予測が可能です。これらの分析手法は出店判断や営業戦略に幅広く活用されます。特にハフモデルでは距離と店舗魅力度から吸引人口を算出し、競合影響を加味した現実的な市場規模を把握できます。このようなGIS活用は商圏評価や立地戦略の精度向上に寄与します。

監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
| 医療経営士/介護福祉経営士 流通経済大学客員講師/共栄大学客員講師 一般社団法人LBMA Japan 理事 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/




