
エリアマーケティングラボ
重回帰分析とは?エクセルを使った分析手法やマーケティングにおける活用事例もご紹介
2025年1月14日号(Vol.125)
はじめに
重回帰分析とは、統計解析、多変量解析手法のひとつで、複数の説明変数と目的変数の関係を分析するための統計的手法です。
重回帰分析は、単回帰分析と異なり、複数の説明変数を使用して目的変数の変化を説明します。これにより、より複雑な関係性を分析し、より正確な予測を行うことが可能となります。
マーケティングにおいては、売上予測や顧客行動分析、市場動向分析など幅広い用途で活用されています。
マーケティングにおいて非常に有用なツールですが、適切な手法で分析を行い、結果を正しく解釈することが重要です。
本記事では、重回帰分析の一般的な世界観をお伝えしつつ、チェーン企業の売上予測について詳細に解説していきます。

重回帰分析の基本
重回帰分析とは、1 つの目的変数と複数の説明変数との間の関係を分析するための統計的手法です。マーケティングにおいては、売上予測や顧客分析など、様々な場面で活用されています。
最終的な重回帰モデルは以下のような計算式となります。※ここではチェーン企業の新規出店時の売上予測を例にします。
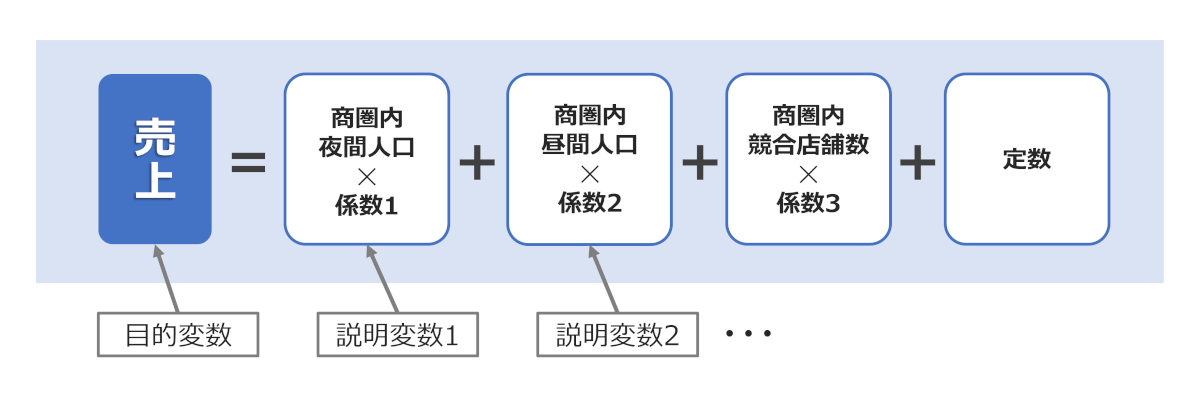
重回帰分析における目的変数は、分析によって予測したい数値やカテゴリを表す変数です。売上予測などマーケティングにおいては、以下の要素を目的変数として設定することが一般的です。
• 売上高:特定期間における製品やサービスの総売上額
• 顧客数:特定期間における新規顧客や既存顧客の総数
• 市場シェア:特定市場における企業の製品やサービスの占有率
• ブランド認知度:特定ブランドを認知している消費者の割合
• 顧客満足度:製品やサービスに対する顧客の満足度
目的変数は、分析の目的や対象となるデータによって異なるため、事前に明確に定義することが重要となります。適切な目的変数を設定することで、分析結果の信頼性や精度を高めることができます。
重回帰分析のメリット
重回帰分析は、複数の要因が関係する問題を分析できるため、マーケティングのさまざまな場面で活用されています。しかし、どんな分析手法にもメリットとデメリットがあり、重回帰分析も例外ではありません。
まずは、重回帰分析のメリットからご紹介します。
- データに基づいた分析が可能 • 過去のデータに基づいて分析を行うため、主観的な判断に頼らず、客観的な分析結果を得ることができる。
- 未来予測の可能性 • 過去のデータから将来の傾向を予測することができる。
- 実用性の高い分析手法 • 分析結果を具体的な施策に落とし込むことができる。(例:上予測結果に基づいて、広告費の配分や商品開発の方向性を決定する等)
• 分析結果を社内で共有することで、意思決定の透明性も高まる。
• 複数の変数を同時に分析できる。(売上予測のように多くの要因が絡む問題を分析するのに非常に有効)
• 適切なモデルを構築できれば高い予測精度を得られる。
• 独立変数と従属変数の関係を分析することで、因果関係を推定することもできます。
• 予測された市場変化や競合状況を把握することで、潜在的なリスクを回避することができる。
• 新商品の売上予測や顧客離反予測などのマーケティング戦略の立案に役立て、マーケティング予算やリソースを効率的に配分することができる。
• 予測された顧客ニーズや市場動向を参考に、より効果的な新製品開発を行うことができる。
• 回帰モデルは各種統計解析ツールだけではなく、Excelでも作成できる。
→ そのためデータさえ揃っていれば分析作業・環境自体のハードルはそう高くない。
重回帰分析のリスクと欠点
重回帰分析には、以下のような欠点もあります。重回帰分析はマーケティングにおいて強力な分析手法である一方、利点と欠点を十分に理解した上で活用することが重要です。
• 適切なモデルを構築するためには多くのデータが必要
• データ収集に時間がかかったり、コストがかかったりする可能性がある。
• 重回帰分析はモデル構築が複雑なため、専門的な知識が必要となり、誰でも簡単に活用できる手法とは言えない。
→ そのためビジネスで利用する際、チームメンバーや経営陣・上層部との合意形成が難しい場合もある。
• 重回帰分析は外れ値の影響を受けやすく、予測精度が低下する可能性がある点にも注意が必要。
重回帰分析の手順
重回帰分析では何を予測したいのかを決めておき、予測したい変数を含むデータがあることが大前提となります。ここからは多店舗展開のチェーン企業の新規出店時の売上予測モデルを重回帰分析によって作成することを例として解説していきます。
STEP1:データ収集
自社の店舗データは既に自社内で保有していると思いますが、各店舗の売上(目的変数)だけではなく、店舗の様々な属性(説明変数)が店舗データに紐づいているとよいでしょう。
さらに3rd Partyデータという外部データも利用します。その中で、いわゆる商圏データ(各店舗周辺の人口統計)もよく説明変数に利用されています。
<自社店舗データと属性(説明変数候補)>
• アプローチ:入りやすさ、切り下げ幅とその箇所数、角地かどうか、視認性など
• キャパシティ:店舗面積、駐車場台数、敷地の間口、座席数など
<外部データ(商圏データなど)>
• 商圏データ:店舗周辺の居住者、勤務者、来街者を計るデータ群
• 競合店舗:競合店舗の店舗数や距離(競合店舗は同業態とは限らない)
• TG(トラフィックジェネレーター):人の滞留を発生させる要素(駅とその乗降客数、商業施設や人気スポット)
• 通行量:店舗前面の歩行者量や自動車通行量
■ 商圏データの一覧
チェーン企業の売上予測で利用できる各種データベースの一覧です。参考にしてみてください。
www.giken.co.jp/datalineup/
STEP2:データの作成と選択
データが揃っていても、重回帰分析で期待する成果を出すためにはデータの事前処理が重要です。ここが重回帰分析にかかる時間全体の7~8割を占める重要な工程です。
<分析に投入する母集団>
• 全店舗のデータで重回帰モデルを作成するよりも、モデル作成用のデータとモデル検証用のデータに分けておくとよいでしょう。目安としてはモデル作成用7~8割、検証用2~3割といった配分です。500店舗ある場合、350~400店舗でモデルを作成し、100~150店舗でそのモデルを検証するイメージです。
• 既存店のデータを元に新店の売上を予測するので、ある程度のサンプル数(店舗数)は必要です。モデル作成に必要な店舗数は50店舗程度がひとつの目安でしょう。
<データの除外>
欠損値やはずれ値を確認しましょう。基本的なところですが、案外見落としがちです。売上額が入力されていなかった、ご入力でデータの値が一桁間違っていたりすることもありえます(欠損値)。
• 欠損値への対処方法:欠損値への対処方法としては、欠損値を平均値や最頻値で補完する方法や、欠損値が存在するデータを削除する方法などがある。
• はずれ値への対処方法:はずれ値を除外する方法や、はずれ値の影響を軽減する方法などがある。また、明らかに特殊要員のある店舗、わかっている店舗はあらかじめはずれ値としてデータから除外しておく観点もある。
<データの正規化>
• 必ず必要という訳ではないが、投入するデータを実数そのままではなく、正規化して投入したほうが精度が向上する場合もある。構成比にしたり、偏差値(スコア)にしたり、主成分分析をかけたり、対数化するといった方法がある。
STEP3:モデル作成
データの準備が終われば、重回帰モデルを作成する工程に進みます。そもそも分析のゴールが売上を予測することとして、最適なモデルが重回帰モデルとは限りません。
近年ではAI・機械学習も進化しており、自社にとってどんなモデルが適しているのか、試行錯誤することが重要です。

とは言え、重回帰モデルは売上予測手法の中では作成に必要なツールや時間、結果の解釈などがAI・機械学習よりは容易であると言えるので、まずは重回帰から始めても良いかと思います。
重回帰モデルはExcelでも作成できます。具体的な方法をご紹介します。

Excelでの重回帰分析
ここからはExcelでの重回帰モデルの作成方法について解説します。元データとして、店舗リストに商圏データを紐づけたものを準備しました。
データメニュー>データ分析を選択し、さらに「回帰分析」を選択します。
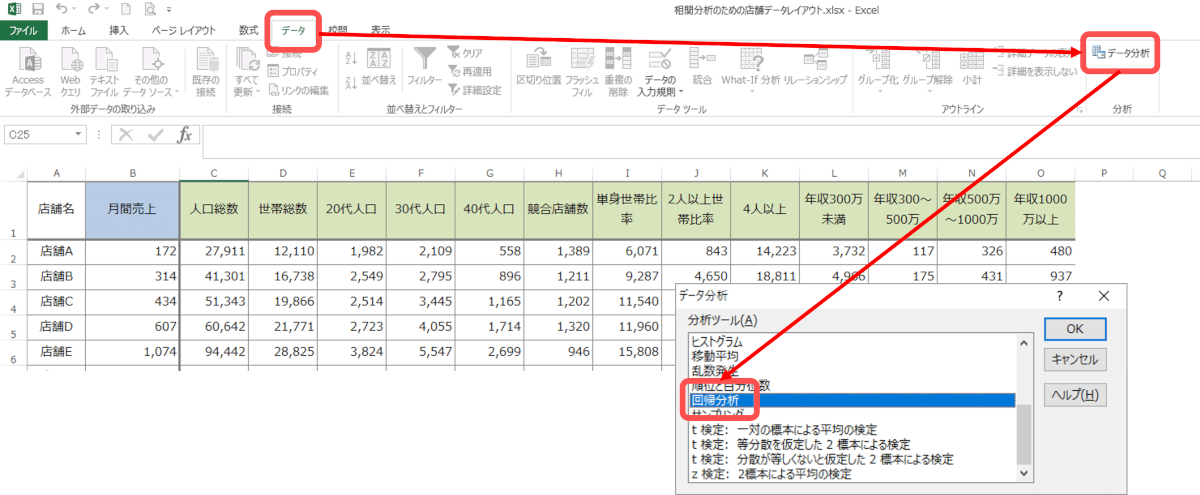
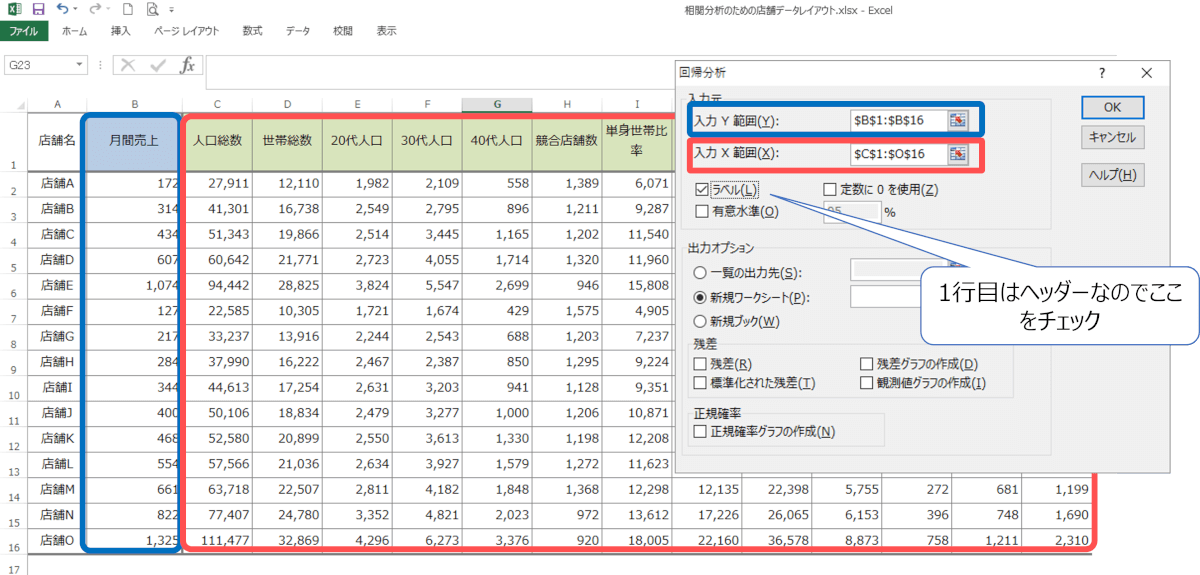
ダイアログボックスが表示されるので、入力元というフィールドでYとXの範囲を指定します。Yは目的変数(売上)、Xは説明変数(商圏データ)と理解すればよいでしょう。
ほとんどのデータの1行目は実質ヘッダー項目かと思いますので、「ラベル」欄にチェックをつけておきましょう。
必要に応じて、オプションを設定します。オプションには、残差のプロットや共分散行列などがあります。出力先を指定してOKボタンを押せば完了です。
■ モデルの解釈
完成したモデル式を評価する工程です。実際の式は下図の②の部分です。
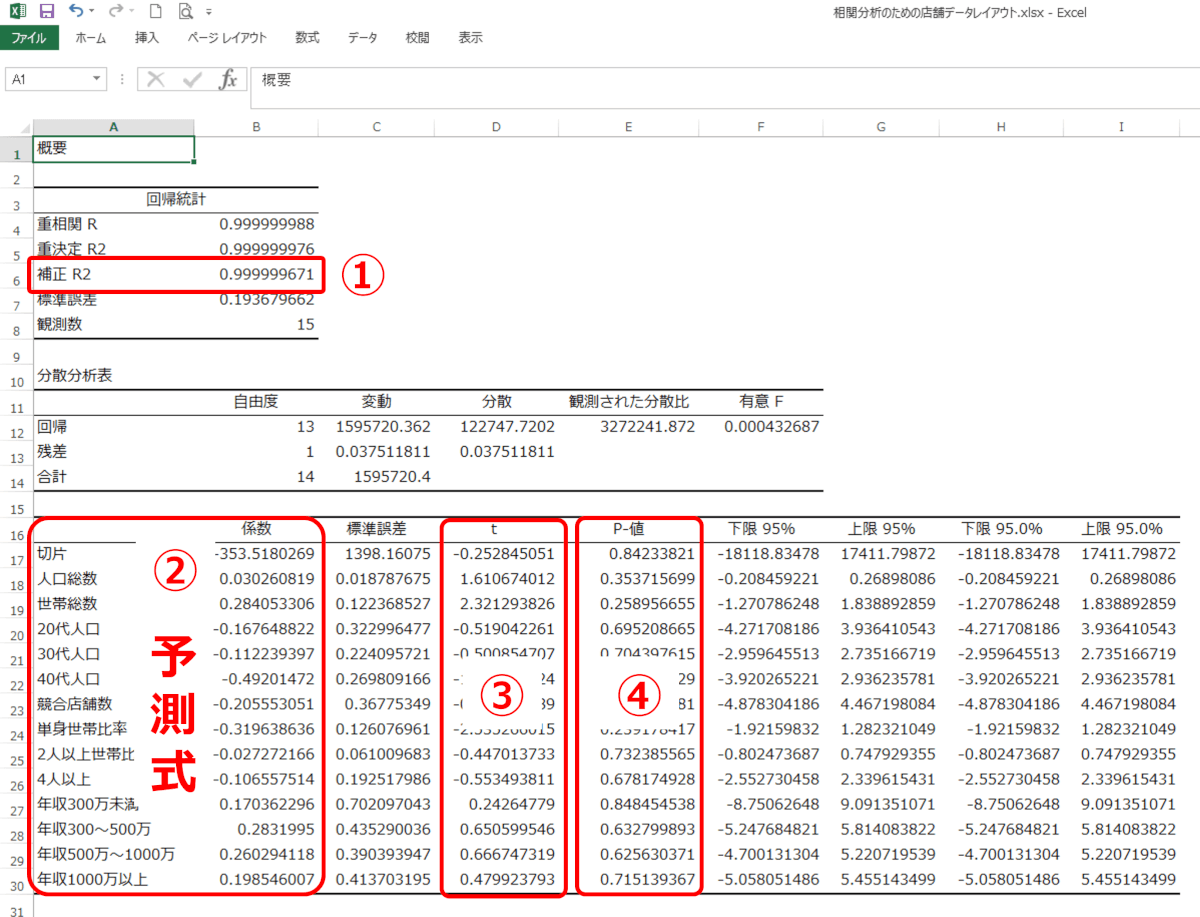
式の精度を評価するためにチェックするポイントはいくつもありますが、実務上、以下の3点は最低見ておくようにしましょう。
• 補正R2
モデルの適合度を表します。予測した売上と実際の売上の相関係数の二乗の値です。0から1の値をとり、1に近いほどモデルの適合度が高くなります。一般的な実感値としては0.6を越えていると一定の精度があると判断できることが多いです。補正という言葉は一般に予測式の説明変数が多いほどR2は高くなるので、それにペナルティを与えるという補正処理がされているという意味です。
• t-値
説明変数が目的変数に与える影響の大きさです。説明変数の変化に伴い、目的変数がどれくらい変化するかを示します。係数の絶対値が大きいほど、その説明変数の影響度が大きいことを意味します。絶対値2以上を目安とすると良いでしょう。
• p-値
係数が偶然ではなく、統計的に有意な結果であるかどうかを検定します。P-値が0.05以下であれば、有意な結果であると判断されます。
その他にも標準化係数、VIF(多重共線性)なども重要なチェックポイントです。
これらはExcelでは出てこないので、別途統計解析ソフトなどが必要となります。
■ 高度な重回帰モデルが作成できるGIS(地図情報システム)
MarketAnalyzer®5は、重回帰分析やクラスター分析、主成分分析機能を搭載したGIS(地図情報システム)。Excelではできない重回帰分析のデータの投入方法や結果の解釈が可能です。
店舗データに対して商圏データを一括集計することも。無料トライアル受付中。
www.giken.co.jp/products/marketanalyzer/
重回帰分析の精度向上のポイント
先にExcelでの重回帰モデルの作成方法について解説しましたが、実際の作業自体はさほど難しいものではありません。ただ、期待する精度を上回るモデルを作成することは容易ではありません。ここでは、精度向上のために留意しておくべきポイントを解説します。
説明変数の選択
重回帰分析では、目的変数に影響を与える説明変数の選択が重要です。適切な説明変数を選択することで、予測精度の高い回帰モデルを構築することができます。説明変数の選択に当たっては、以下のポイントを考慮する必要があります。
• 理論的妥当性
目的変数と説明変数の間に理論的な関係があるかどうかを検討します。理論的妥当性のある説明変数を選択することで、モデルの解釈可能性が向上します。
• 統計的妥当性
説明変数と目的変数の間に統計的な相関関係があるかどうかを検討します。統計的妥当性のある説明変数を選択することで、モデルの予測精度が向上します。
• 多重共線性
説明変数の間に強い相関関係がある場合、多重共線性が発生する可能性があります。多重共線性はモデルの精度を低下させるため、説明変数の選択に当たっては、多重共線性の有無を確認する必要があります。
• データの質
説明変数として使用するデータは、正確で信頼性がある必要があります。データの質が低い場合、モデルの精度が低下する可能性があります。
これらのポイントを考慮した上で、目的変数に影響を与える可能性のある説明変数を絞り込みます。絞り込んだ説明変数を使用して、重回帰分析を実施し、予測モデルを構築します。
多重共線性を避ける
重回帰分析の欠点として、多重共線性のリスクが挙げられます。これは、説明変数同士が強い相関関係を持つことで、回帰式の精度が低下したり、係数の解釈が困難になる現象です。
多重共線性が発生すると、以下のような問題が生じます。
• 係数の不安定性:説明変数の係数がわずかに変化しただけで、大きく変動する可能性がある。
• 係数の解釈の困難性:どの説明変数が実際に売上予測に影響を与えているのか、判断が難しくなる。
• 予測精度の低下:回帰式の予測精度が低下し、信頼性の低い予測結果が得られる可能性がある。
多重共線性のリスクを回避するためには、以下の対策が有効です。
• 説明変数の選択を慎重に行う:説明変数同士の相関関係を分析し、相関関係が強い変数は除外するなどの対策が必要。
• 主成分分析などの手法を用いる:主成分分析は、複数の変数を統合して新しい変数を作成する手法であり、多重共線性の影響を軽減することができる。
• データを正規化する:投入する説明変数を、実数ではなく構成比にしたり、スコアや対数にしたりする。
質的データも説明変数として投入してみる
質的データの数値化については、尺度化とダミー変数化の2つの方法があります。
尺度化は質的なデータを数字の尺度で表現する方法で、データの正規化と似ています。ダミー変数化は質的なデータを0と1の数値で表す方法です。
店舗の売上予測では、看板の視認性評価の際、遠くから見えれば5、近くまでいかないと見えない場合1点などとしたり、駐車場台数ではなく、駐車場の有無を0と1で表現するなど行います。
競合店舗の影響も加味する
商圏データとして各店舗周辺の人口などを説明変数に投入しますが、例えば、単純な店舗1km圏内の人口が5万人という数値ではなく、1km圏内の競合の影響度を加味した結果、人口は2万人となり、その2万という数値を説明変数とするというイメージです。
「商圏人口」は5万人で、競合の影響を加味した「吸引人口」は2万人というように言います。
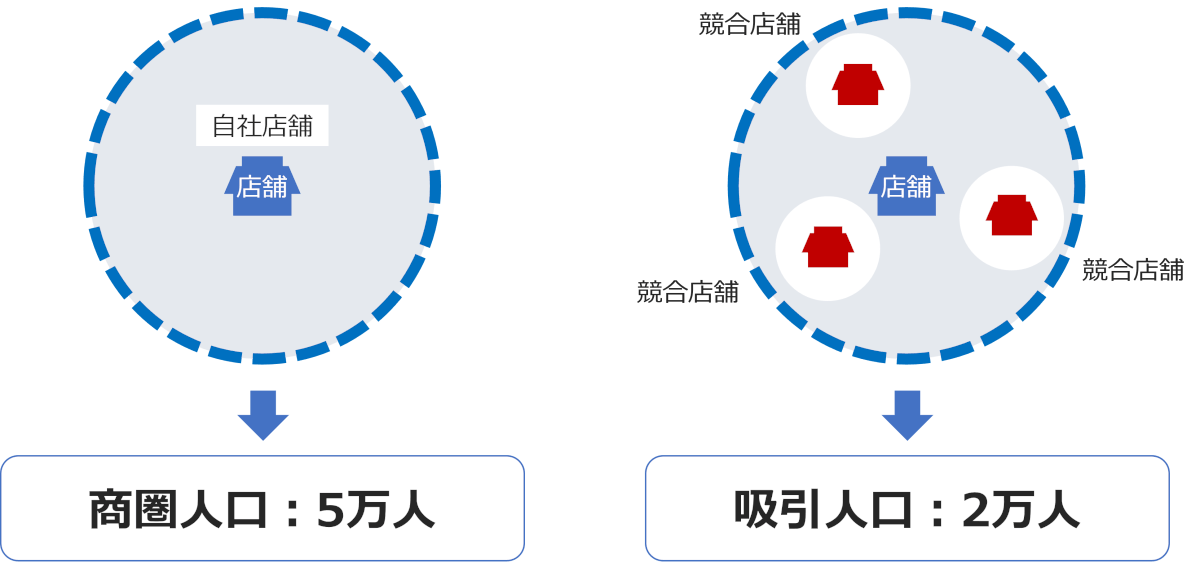
<吸引人口の算出方法>
• 最も単純な方法は、上記の図で言うと、商圏人口 ÷(自社店舗数+競合店舗数)= 5万人 ÷ 4店舗 = 1.25万人という計算ロジック。
• もう少し精緻に算出する方法として「ハフモデル」という吸引モデルもあります。各エリアと各店舗の距離と魅力値を用いる方法。
■ ハフモデル(グラビティモデル)分析について
www.giken.co.jp/glossary/huff_model/
店舗を分類する
チェーン店舗の出店形態、出店立地は必ずしも同じパターンではありません。ベッドタウンに出店する場合、ビジネス街や繁華街に出店する場合と様々です。
異なる立地パターンそれぞれをグルーピングし、立地パターングループごとに重回帰モデルを作成します。ベッドタウン立地パターンのモデルでは居住者系データが有効な説明変数となり、ビジネス街立地では勤務者系データが有効だったりします。
<店舗のグルーピング方法>
店舗のグルーピング、分類方法も様々あります。単純なものですと、各店舗周辺の夜間人口と昼間人口の比率(昼夜間人口比)で分類する方法もあります。複数の商圏データや変数で統計学的に分類する方法としてクラスター分析があります。
■ クラスター分析機能を搭載したGIS(地図情報システム)
MarketAnalyzer®5は、重回帰分析やクラスター分析、主成分分析機能を搭載したGIS(地図情報システム)。店舗データに対して商圏データを一括集計することも。無料トライアル受付中。
www.giken.co.jp/products/marketanalyzer/
人流データを説明変数に投入する
チェーン店舗の重回帰分析による売上予測モデルに投入する説明変数として、店舗の属性(面積や間口など)と商圏データ(店舗周辺の人口統計)は一般的によく採用されるデータ項目ですが、商圏データの人口統計はその調査年度によっては鮮度という意味で苦しい場合もあります。そこで位置情報データ(人流データ)を投入すると精度が向上する場合があります。
<人流データを投入して精度が向上した例>


■ 人流データを搭載したGIS(地図情報システム)
・MarketAnalyzer® Traffic
全国125mメッシュ単位で平日/休日、時間帯別の滞留人口を搭載。
www.giken.co.jp/products/marketanalyzertraffic/
・KDDI Location Analyzer
全国どこでも任意の地点の滞在者や来訪者の分析が可能。
www.giken.co.jp/service/kla/
※どちらも無料トライアルが可能です。
重回帰分析以外の売上予測手法
売上予測手法には、重回帰分析以外にも様々な手法が存在します。主なその他の手法
• ハフモデル分析(グラビティモデル分析): 複数の店舗の売上を、店舗間の距離や人口分布などを考慮して予測する手法です。
• 類似店検索: 過去データから、対象店舗と類似した店舗の売上げ実績を参考に予測する手法です。
• AI・機械学習:
これらの手法を組み合わせることで、より精度の高い売上予測を実現することができます。
ハフモデル分析(グラビティモデル分析)
ハフモデルは、マーケティングにおいて、顧客が特定の店舗や施設に来店する確率を予測するのに使用される手法です。
これは、物理学における万有引力の法則に基づいており、顧客の来店確率は、店舗の魅力と顧客との距離に比例し、距離の2乗に反比例すると考えます。
ハフモデルの分析には、店舗の魅力、顧客との距離、競合店舗の存在など、様々な要素が考慮されます。
店舗の魅力は、店舗の規模、品揃え、価格、知名度などによって評価されます。顧客との距離は、顧客の居住地と店舗の距離によって算出されます。競合店舗の存在は、競合店舗の規模、距離、品揃えなどによって考慮されます。
ハフモデル(グラビティモデル)分析については以下の記事も参照してください。
www.giken.co.jp/glossary/huff_model/
類似店検索
類似店検索は、重回帰分析以外の売上予測手法のひとつです。新規出店候補地の商圏構造や競合店舗の配置などを解析し、その構造と似通った既存店の売上を参照するという手法です。
複雑なモデルを駆使するよりも社内外への説明が容易なので重回帰分析と並び多くのチェーン企業の店舗開発で採用されています。
■ 類似店検索機能を搭載したGIS(地図情報システム)
MarketAnalyzer®5は、類似店検索機能を標準搭載したGIS(地図情報システム)。店舗データに対して複数の商圏データをスコア化し、その波形パターンで類似店を抽出します。無料トライアル受付中。
www.giken.co.jp/products/marketanalyzer/
重回帰分析による売上予測の失敗事例
重回帰分析は、マーケティング活動において有効な手法ですが、誤った運用方法では失敗する可能性があります。
実際に起こった失敗事例をいくつかご紹介する例を参考に、重回帰分析を正しく活用して自社のビジネス課題の解決の成功率を高めるために活用していただければ幸いです。
プロジェクトの理解と全社共通のゴール設定
<事象>
経営陣より、新規出店時の売上予測モデルを作って欲しいとの指示が店舗開発部隊に降りてきて、現場部署ではモデル構築のナレッジがなかったため、外部のコンサル会社に依頼することとした。
モデル構築には外部データが必要になり、GIS(地図情報システム)ベンダーとコンサル会社と自社の3社の体制で売上予測モデル構築プロジェクトを推進。
コンサル会社はビジネス理解がなく、統計学的な数値(例えばR2値が0.7以上など)をゴールとしていたが、数値的目標は達成しても、現場部署からすると採用された説明変数やその係数が経験と勘と合わず、受け入れられない。
また、現場部署の担当も複数窓口があり、都度人も入れ替わり、何がプロジェクトのゴールなのかが曖昧なまま時間だけが過ぎ去り、全体的に息切れして成果も出ないことからプロジェクトが停止となった。
<反省点>
プロジェクト開始時に、外部企業と自社、自社内の現場と経営層とで、何を持って成功とするか、どこまでの内容(式の精度)がでればゴールなのかを予め定義しておくことが重要。
統一基準での実査データ収集
<事象>
売上予測モデル構築時のトライ&エラー時、店前通行量データが有効な指標となるという仮説を立てた。
外部業者に調査してもらうとか、人流データを用いるといった手段を取れるほど予算がなかったため、各現場の店長に自分の店舗前の通行量を調査するように依頼。
ただ、調査の設計やマニュアル化があまく、ある店舗では歩行者量のみで、ある店舗は自動車の中でも乗用車のみといった不整合や、ある店舗では平日の午前中、ある店舗は土曜日の夕方など、出来上がったデータの基準がバラバラで、結局モデルに投入できるものではなかった。結局やり直したが、店長の貴重な数時間✕数百店舗分の目に見えないコストが無駄になった。
<反省点>
人力で実査調査する際には、事前の緻密なマニュアル化が重要。出来上がったデータにブレがないようにする。
■ 店前通行量を搭載したGIS(地図情報システム)
MarketAnalyzer® Trafficは、全国の道路単位の通行量を搭載したGIS(地図情報システム)。全国どこでも任意の道路の通行量と、平日/休日別、時間帯別、性別・年代別にワンクリックで調査することができます。無料トライアル受付中。
www.giken.co.jp/products/marketanalyzertraffic/
社内での再現性とモデルを育てる環境
<事象>
自社店舗を商圏ボリュームによって2つに分類し、それぞれの分類ごとに重回帰モデルを構築した。
1つ目の分類の重回帰モデルは、統計学上も経験上も期待値を超えており、モデルとしては精度が高いものが完成。
ただ、2つ目のモデルは重回帰では当てはまりがわるく、外部のコンサルティング企業に依頼して、機械学習(ニューラルモデル)によってモデルを構築した。
彼らの今後の出店エリアとして、2つ目のモデルを当てはめるような立地の優先順位が高く、重回帰モデルは事実上運用がされず、ニューラルモデルで予測売上を出すことは自社内ではツールがないため、都度外部のコンサルティング会社に依頼、結果が出るまでのタイムラグや、そもそもの予測業務のコストがかさみ、費用対効果が悪く、だんだんと使わなくなった。
<反省点>
ある程度精度を犠牲にしても、そのモデルの運用が自社内で完結できるような環境も含めて構築しておかないと、結局現場実務で運用されなくなってします。
まとめ
重回帰分析は、マーケティング領域において、売上予測をはじめとしたさまざまな活用事例があります。複雑な手法ではありますが、データに基づいた分析を行い、未来予測や実用的な施策立案に役立てることができます。
しかしながら、適切な分析手法の選択や質的データの数値化など、注意すべき点も存在します。
適切な理解と運用により、重回帰分析はマーケティング活動における強力な武器となるでしょう。
〇 重回帰モデルを使った、高精度の売上予測方法について解説したコラムはこちら
〇 毎月開催!お役立ちセミナーはこちら

監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
| 医療経営士/介護福祉経営士 流通経済大学客員講師/共栄大学客員講師 一般社団法人LBMA Japan 理事 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/




